arkaine - an experiment in AI tooling
tl;dr
I talk about the ideas behind and efforts expended to build my AI framework, arkaine. What worked? What didn’t? Does it have a future?
arkaine, briefly
I decided a few months ago to create an AI framework for making agents. I use that term loosely because the actual definition changes based on what your focus is, what level of understanding of the inner workings of these models are, whether or not you were born under a blue moon, etc. The definition that I used for arkaine, which I don’t necessarily think I would even use as my personal definition of agent is:
- a·gent /ˈāj(ə)nt/
-
An entity that uses an LLM, possibly in combination with other tools, to perform a task
This framework, which I called arkaine [Docs] | [GitHub], ended up being quite capable, powering a couple of my projects. I released it, encouraged other people to try it out, saw that virtually no one did (but that’s okay!), began making example projects for it, discovered that one of the projects was really useful and possibly a good idea for a business (more on that later) and ultimately stopped work on it to focus on a startup for idea.
Feel free to jump around the article by the way, depending on what you’re interested in. This is very much not an article with strict linear dependencies. If you want the full story then read on, but if you are interested more in the tech jump right to Built with arkaine to see what I made with the framework or The Inner Workings to see my breakdown of the framework’s core components and my review of what went right/wrong.
The why
I had three reasons for starting arkaine. In order of increasingly esoteric justification:
-
Tool calling was just hitting the scene, and tool calling was only available at the time on OpenAI and Google’s offerings - Claude didn’t have it yet, and local models like llama didn’t support it either. Seeing the importance of tool integration (since I kind of implemented it in my now ancient-in-AI-timescale Master’s thesis having LLMs control robotic task planning) I thought we should have frameworks that empowered tool calling across all models.
-
I wanted to make sure that I could fully understand what was being done for me in the background in many of these frameworks - the same reason I tell junior engineers not to use an ORM (Object Relational Mapping) framework for SQL databases in their apps when learning. It’s important to understand what’s happening for you and why. arkaine was a way to learn, if nothing else.
-
I didn’t like the other AI frameworks. I can try to justify my reasoning with a long drawn out breakdown of langchain and others (though when I started langchain was the framework on everybody’s mind), but I’ll just preface it with I just didn’t like what I saw. You might accuse me of some level of arrogance or a subject of NIH (Not In Here) syndrome, but really it was just that the approach of these frameworks didn’t sit right with me. Though crewai came out after I started, and that seems to be the closest to the vibe I was going for.
That’s the story as I remember it. It was also nice to be producing a generic tool for others to build off of - much of my open source project work tended to be more isolated one-offs than an ambitious set of reusable components.
At some point during development (around the time I decided that functions and agents were interchangeable syntax wise, a thing I’ll explain later) I also came up with the idea that maybe a framework focused on AI for the rest of us - IE dead simple agent programming and composability for DIY techies could be a cool angle. The inspiration of this was taken from Arduino shields (or, for Raspberry Pi, hats). Plug and play modules for a “easy as possible” batteries included approach so that even children could start to produce real devices.

That’s the pitch I used, at least, when I was given an opportunity to talk about it for 20 minutes; but found out minutes prior it was really only 5 minutes so I had to compress my presentation on the fly. I still kind of think that creating a more developer and hobbyist friendly methodology for integrating agentic (especially local!) AI into DIY projects or plug and play pieces for AI is a potentially powerful vector for inspiration; I just very much failed to target those people in communication and design.
At one point the project name was actually composable-agents to reference the idea of this plug and play approach.

Built with arkaine
I had built quite a few working (varying degrees of done-ness, admittingly, as with all projects) with arkaine ultimately powering it. This is on top of the massive amount of work put into the various tools and integrations built into arkaine itself.
HiredCoach
![]()
I’ll be talking more about this soon. I started creating hands-on examples to act as tutorials to get people interested in using arkaine, and act as a tutorial project. One of the first projects was an agent that, given a resume, a job description, and my internet search enhanced research agents, create AI voiced interview questions targeted at the user’s background as if they were the hiring manager for that job.
I tested it across a couple of friends, several with deep technical science backgrounds, and the general feedback was that it was quite good at asking tough questions.
I realized that if I paired it with some feedback mechanisms it would actually be a pretty useful product.
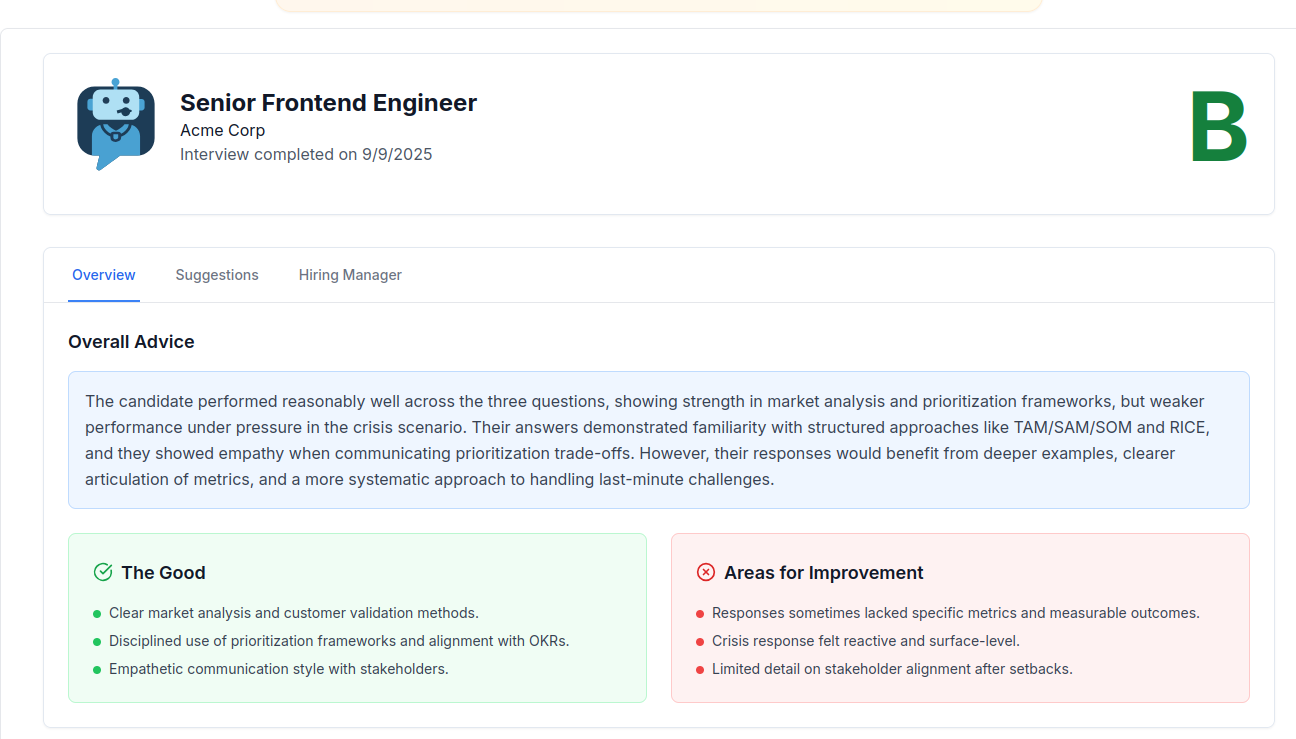
…so I created HiredCoach, which is launching soonish. The quasi-private beta provided immeasurably valuable feedback (mostly positive too!) that caused me to change up and expand the original product vision, but the core agents are still powered by arkaine.
eli5equation
Hosted here.
Since I host a lot of AI and reinforcement leanring research paper club talks for the local AI group SDx I find myself constantly butting heads with grokking mathematical notation. I try my best to break them down into set chunks of “what is this equation doing?” to try and see the flow as I would a program. When I present the math (a good example), I like to break them down into per-section chunks, but this could take hours to break down and prepare graphics for more complex papers. To make my life a tad bit easier, I threw together eli5equation one evening.
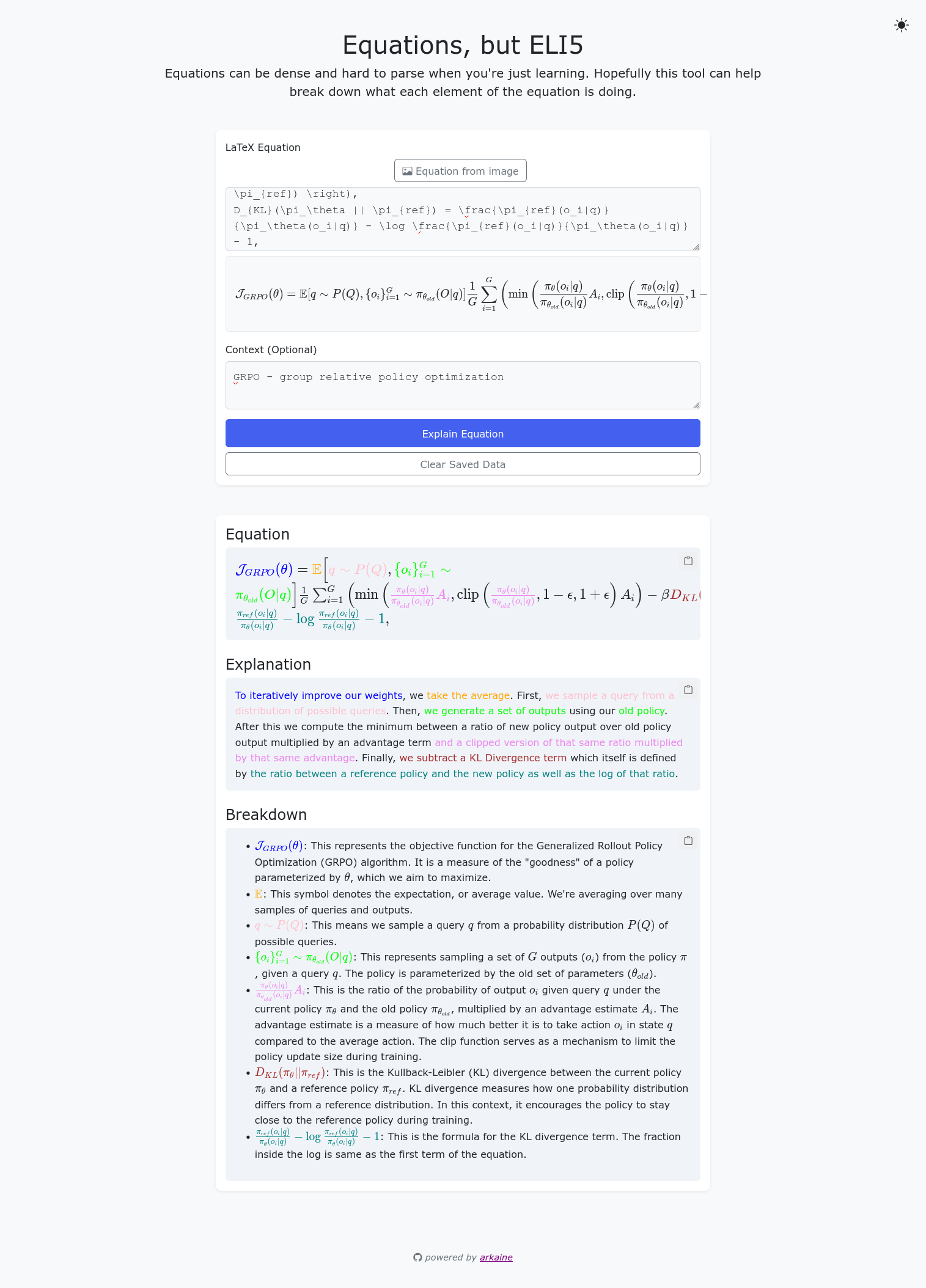
Given the latex for an equation (with a handy image to latex converter - works fine with handwriting, whiteboard, and screenshots), a set of context (like a copy/paste of the research paper section), the agent will break down the equation piece by piece, explaining what the equation is describing/doing in the context of the paper.
It’s been pretty invaluable for deep diving research papers; one of my go-to tools. I’ll jump back to it some day to make it a neater application with some cacheing to make it more user friendly.
genpersona

genpersona was a few hour project at a hackathon with another dev. Whether its development will push forward is an open question.
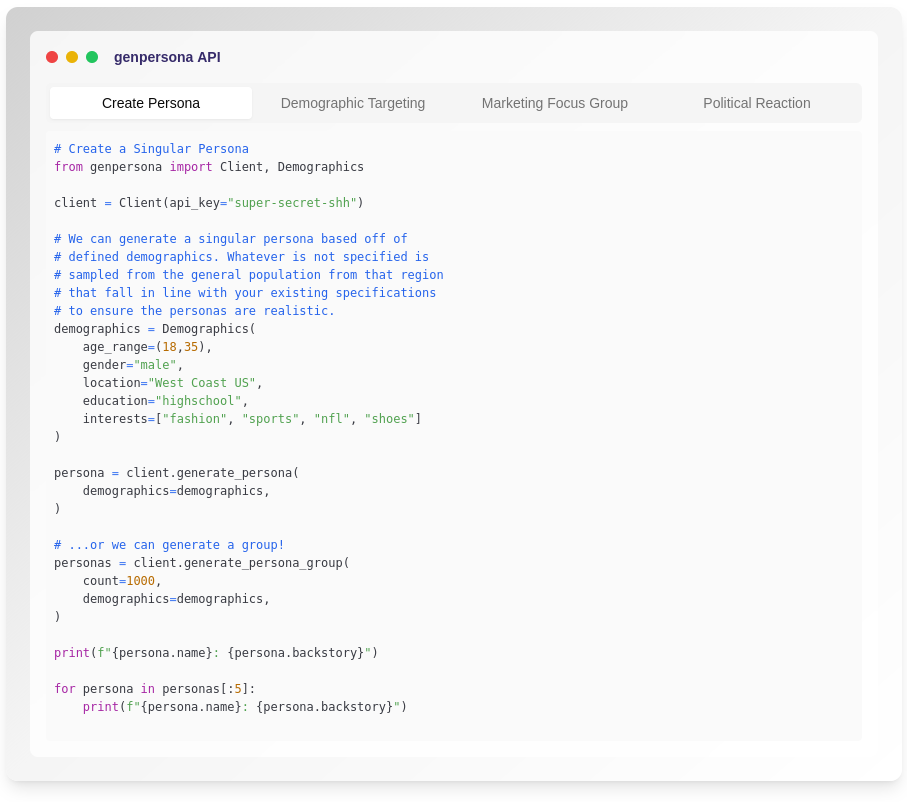
genpersona essentially asked - since AI can be primed to act as a set of personalities and can also generate a third person analysis of what another might be thinking, could we prime that together as an API? Imagine running highly targeted community or population-specific focus groups at scale on demand via AI simulation. Hence this project - a generative persona engine. We’ll see if there is more to talk about on this one in the future.
Personal Researchers
Most of this work was built into arkaine after pumping out a prototype in a hackathon. You can see a complete code walkthrough in the research agent example | [code]. It was by far one of my most useful standalone agents. Heck, the researchers described within sit within HiredCoach’s internal agents and powers the product’s core features.
The goal is straight forward - given a query, generate a bunch of research. The agent’s design acted as a generic interface that could construct different kind of researchers based on provided tools.
For instance, a Researcher would be attached to a set body of knowledge - the general internet, but could be refined; think arvix, or PubMed specific researcher, or one with a subset of textbooks or your own documents to query. It would then follow the flow of:
- Generate a set of queries to search for
- Perform the search across a set of
Resources - Judge the relevance of the
Resources before consuming them - Generate
Findings - essentially a resource linked set of knowledge extracted from a document - from each Resource found.
These could then be combined into more complex flows, like the IterativeResearcher, which:
-
Specify an overarching topic of research.
-
A TopicGenerator agent generates a list of sub topics to break the problem down into sub questions
-
A specified researcher (defaulting to a WebResearcher) searches their body of knowledge for information on that specific topic. Multiple kinds of researchers can be utilized.
-
The research returns
Findings which are combined. -
A TopicGenerator agent is utilized to create a new set of sub-topics based on what we’ve discovered thusfar. I think you can see where this is going
-
This process continues until the topics are depleted, an iterative depth limit is hit, or a time limit is hit.
The resulting Findings are collected and returned, or fed into a generator of some sort (like to generate a report, direct answer, into a chat agent, etc). I experimented with slide generation, toyed with podcast generation, and a few other outputs that never made it as a completed built-in toolset.
Inner Workings
Most of the inner workings are best described by the main documentation, with the “My First Agent” example being particularly definitive for “getting” arkaine. For clarity I’ll still define a few key terms I’ll be heavily leaning on.
- 🔧 Tools
- Tools are functions (with some extra niceties) that can be called and do something. That’s it! Those niceties included context (to be explained) tracking, asynchronous calling built in, descriptive arguments and examples, and more. The goal was to make it so that calling an agent is no different for the end user to calling a function.
- 🕸️ Context
- Context provides thread-safe state across tools. No matter how complicated your workflow gets by plugging agents into agents, contexts will keep track of everything. These ended up being complicated but oh-so-useful when building with arkaine.
- 🤖 Agents
- Agents are tools that use LLMS. Different kinds of agents can call other tools, which might be agents themselves!
- 🏗️ Backends
- Backends are systems that empower an LLM to utilize tools and detect when it is finished with its task. ReAct, for instance, was the most popular. I built a few others for some reason (again, more on that later).
- 📦 Connectors
- Connectors are systems that can trigger your agents in a configurable manner. Want a web server for your agents? Or want your agent firing off every hour? Or your agents to respond to certain e-mails? Integrations that could do all the heavy lifting of taking your agent from “works when I call it” to “deployable mini app”. I made these to easily handle the annoying “now what” moment after you make a cool agent and to hook it up to systems people actually wanted to run.
Reviewing arkaine
The good
Context
Context ended up being the heart of arkaine’s agents, acting as a workhorse for any complicated workflow.
Context is passed between each agentic call. It creates a directional tree wherein a context could have a singular parent and n children. It tracks virtually everything. What you’d expect:
- Arguments passed
- Results returned
- Exceptions thrown
…but also provided a per context threadsafe data store - several of them. Given a context ctx you could safely do ctx["key"] = value or perform operations on it - it was stored local to that context. ctx.debug["key"] was a context-level debug data store, only saving values if a global configuration option was enabled. ctx.x["key"] wherein x refers to “execution” was an execution level context that shared between all contexts within the tree.
The damned coolest feature was the retry ability. Since arkaine gives all tools contexts for execution no matter what the user does, and those contexts are serializable and can be saved/loaded, you can essentially reload the state of the agent at any point in the process. retrying would typically mean clearing the exception and re-running the tool with the same input, but if there error was further down into the tree execution - within some sub child - the context would dial down to just that context and run from there. This means if you provided a fix in the code for that tool you can continue the execution as if you were never interrupted. The flow tools were built to have specific retry methodologies for their specific use, allowing retry to isolate the problematic child, rerun that, and skip redoing a significant amount of work.
The retry feature worked fantastically enough that I’m tempted to break it out into its own library for non arkaine long running process usecases.
Tool definitions
One of the core ideas was to allow any model to utilize tools. Sure there are several smaller models that can’t utilize tools well, but I wanted to be able to plug any individual model in and, assuming that it had sufficient instruction following abilities, to control tooling. This means that early on I realized I needed a programmatic method to not only define tools for LLMs but to allow a developer to programmatically specify how to describe those tools to the model. This could be converting it to a specific API friendly format or a human readable format to feed directly to a model of choice.
…But since I wanted to keep things easy for new developers, I knew I’d have to some way to handle just simple function passing. I created toolify to act as a decorator to convert any function into a tool, wiht programmatic docstring parsing to extract argument and return descriptions. This worked great and was pretty cool!
PythonEnv Backend
The PythonEnv was just straight up fun to make. Inspired by CodeActions, PythonEnv was an attempt to have the tool LLM try to create executable code in order to perform whatever task it’s assigned.
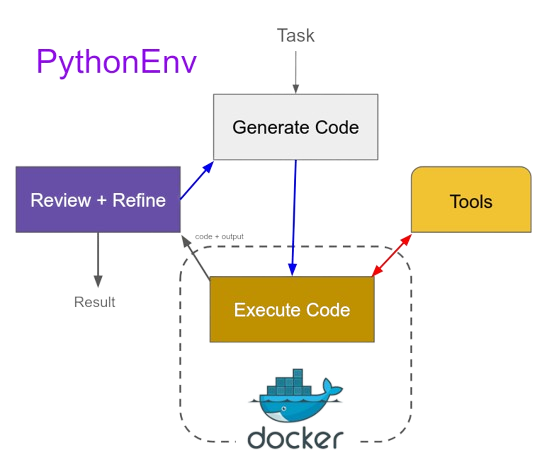
To provide additional tools for the model to call, the LLM is primed to know that the tools exist and informed they’ll already exist within the scope of the code it writes as functions.
These functions actually call a preconfigured socket connection that allows the host backend to interact iwth the internal docker container. If a tool is called, it dials out to the host backend, which then calls the tool normally. The results are fed back into the contianer, which is waiting for its response as any other function. Any output - printing, returns, or exceptions - are sent to the host bakcend for the LLM to utilize to judge its success and inform next steps.
I want to extend this to a direct live session REPL instead of a single fire code execution agent.
Documentation
Documenting a project in a manner that allows others to utilize the project is hard. While I didn’t have many users, what few people did try it out commented that the documentation was pretty great. The act of documenting the project also highlighted user flow issues and forced me to reconsider several design choices for how the tools interacted.
Spellbook
Spellbook was a server tool that utilized all of the event listeners and socket connection work I built into arkaine to provide a web interface for tracking execution state of agents in a human usable interface.
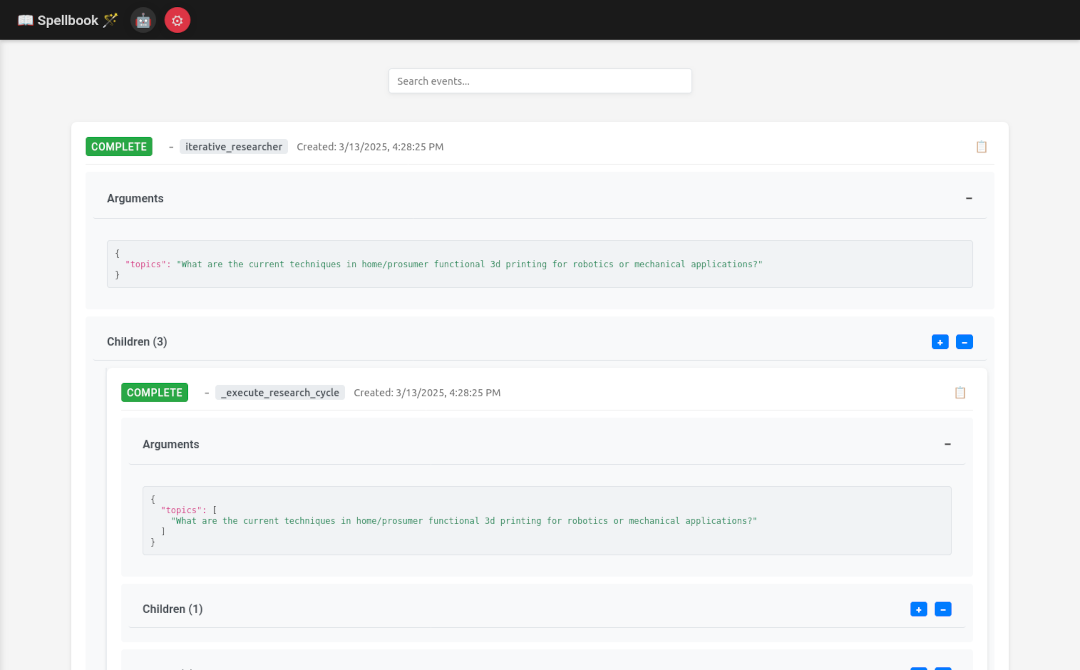
It allowed you to read tooling documentation, trigger agents manually, and watch execution of agents as they fired off. Debugging became massively easier with this tool.
I had some great ideas for “request a tool and have an agent build it” to extend spellbook but never got to that.
The weird
Flow
Since everything is a tool, I surised I could have tools that act as flow control for composing larger and more complicated tooling. This is where the idea of the composable agents came through.
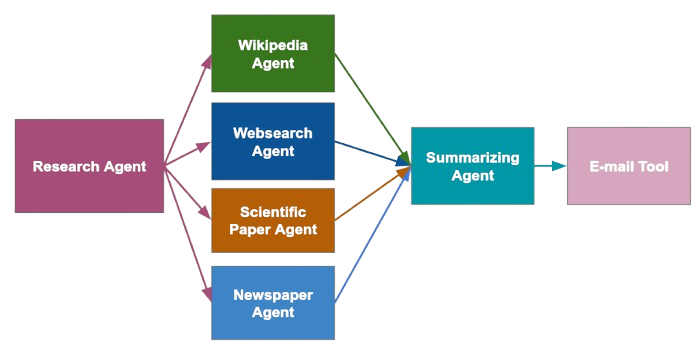
This worked well, but resulted in some extreme oddities.
The most commonly used were:
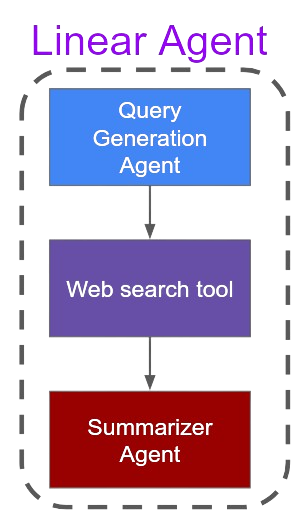
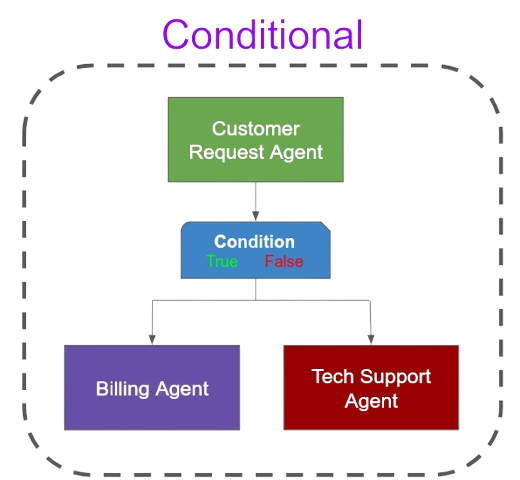
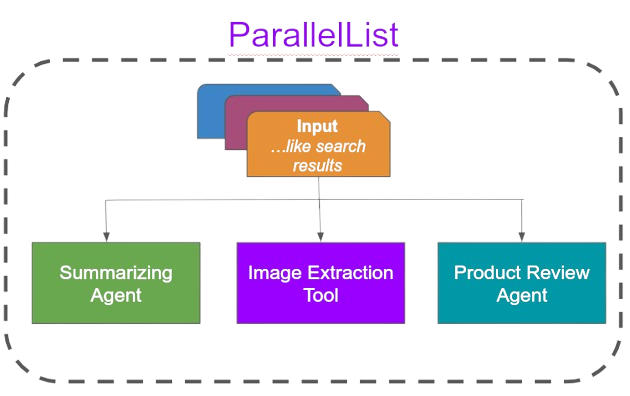
These all worked great, and ultimately unlocked the retry feature I talked about earlier. But I quickly found while building agents that, while flexible, it quickly became unwieldy. Since each flow agent is itself a new agent, and we’re essentially heavily nesting, the context and flow of actions through complex agents quickly exploded.
Event Listeners
Throughout the tools, contexts, and datastores there existed several event listeners. This originally was going to power the debugging tools and ability for agents to react to what was happening within their children, but it ended up being a confusing mixture of techniques that made the agents quite noisy in their broadcasts.
DataStores
I created a ThreadSafeDataStore to expand the ability of the context to store data throughout the execution of the agent. This was necessary to a point, as I needed to ensure that parallel executing agents could make use of data stored in the context without the user having to worry about thread safe data access. The reason I created the class was to expand the capabilities.
A number of helper functions were created that allowed typically multi-stage steps to be performed on the data in a thread safe approach. For instance, .increment would read the increment the contained value; .append and .concat would appropriately modify the data safely. .operate allowed you to specify a modiciation function that would return a locked copy of each specified key’s value and would unlock the value once you returned the modified values for any possible operation.
A network event broadcaster was inserted so that debugging tools like Spellbook could track the value of data being passed through the context as the agents progressed through their execution flow.
The bad
Communication
Trying to convey ideas in a manner that can properly convey the inspiration and excitement that I have is not easy. Or, at the very least, is a skill I lack.
Whether I require a time of self reflection for that skill, or if there was another path towards delivering that inspiration to others, I lacked it for this.
Despite talking about it at several meetups, doing the documentation to onboard people, and trying my hand at a Discord channel to support users and ecourage others to try it out, I never got the response I was looking for.
Timing
arkaine was a solo project over a period of time that resulted in a Cambrian explosion of AI tech. New models, features, and standards were evolving so rapidly that no one could possibly keep up.
The landscape changed heavily, leaving arkaine behind in some ways. Multimodal support is lacking because when it was started too few models could handle it. The flow of non text artifacts into models needs to be baked into the idea of the models, and that would probably take some significant reworking.
MCP exploded onto the scene well after arkaine was started, and would have probably heavily influenced early attempts to network.
Contexts, again
Since most agents of actual use were composed of several tools which in turn would be composed of several flow tools, contexts became unwieldy beasts very quickly. Mapping out what happened and where could become quickly a problem.
There were also oversights. They couldn’t handle artifacts like files, images, audio, etc - only text. You could pass the path to one but it meant a lot of application specific coding.
They were also unwieldy and had some obvious oversights for their memory footprint. For instance - arguments passed into a linear flow tool would be be repeated as its passed into children - the recorded output would be similarly doubled as the output of that child gets fed into the input of the next child. Similarly the output of children were often the output of a parent agent, which in turn was the output of another parent tool, and so on. This meant that contexts exploded in memory quickly, and were unwieldy to read even with Spellbook to make it human readable. Much of Spellbook’s usage was shrinking down the contexts to try to avoid the extraneous reading for large bodies.
Imagine a research agent, that was ingesting entire pages, creating multiple findings that were a paragraph or two each, then constantly passing these to sub agents for further analysis - the context becomes a small novel and exercise in obtuseness in no time.
Errors and Stack Traces
Speaking of unwieldy, I’m sure it takes no bit of imagination to picture how horrific the stack trace hell of deeply nested parallel arkaine tools calling oneanother. The Flow tools being standalone tools and allowing complicatd branching made it only worse.
The result that was, even with attempts to improve the Flow tooling to wrap and clean up some stack traces debugging a broken agent often became a headache, usually meaning deep dives of gigantic stacktraces.
Since I wanted to target developers of all skill levels to build increasingly complex agentic workflows, this was a definite shortcoming. If you want easily used frameworks and tooling, you truly need to think through how stack traces are presented to your user and what level of visibility you’re either granting them… or inadvertantly obfuscating.
Backends
Backends were responsible for preparing the input into LLMs, instructing them how to communicate with us for their given task, and then parse their output for tool calls if needed. As the docs describe them:
A Backend handles:
- Formatting the tool’s descriptions and arguments into a consumable format for the LLM.
- Calling the LLM and then parsing its response to determine if the model has called any tools.
- Parsing the tool calls and then…
- Calling in parallel each tool, and on return…
- Formatting the results of the tool calls into a consumable format for the LLM, repeating until…
- The LLM appropriately responds that it is complete.
This decision was made because it was still unclear at the start of arkaine’s creation what the best methodologies for calling tools was. Most providers did not provide tool calling APIs yet, and most local models didn’t have any techniques for it too. The hope was to provide support for multiple types of backends - ReAct, Tree of Thoughts, self consistency, MCTS, etc.
Unfortunately that act of having to explain the backend to the user, let them choose it, handle the prompting differences to the models for each agentic task, and several other oddities made utilizing backends a pain in the butt. Especially annoying was that ReAct as a backend or directly utilizing the growing tool calling capabilities of models made the entirety of this feature extraneous.
Nonexistent artifact support
As I mentioned before, multimodal models were a rare thing when I started arkaine. Now models can ingest all kinds of inputs. Even with just text-focused LLM output, I constantly found a need to pass varying artifacts from images to audio to pdfs across agents.
The lack of built in support to handle this resulted in routine headaches and weird routing tricks with contexts - a consistent code smell to agents that followed that pattern.
Network-Second instead of Network-First
MCP proved that distributed agents were going to be the way forward - there is too much to gain from having standalone sub agents and parallel compute for long running agentic tasks.
Network connection between arkain agents were considered and planned, but before MCP was a thing. Having networked connections between agents being an afterthought showed whne working with it; agens were more expected to be monolithic than distributed as a result.
No coding agents, sort of
Coding agents, as we use them today, exploded in popularity afterwards - mostly because they can be surprisingly effective. The reason we see so many popping up is because its quite an easy pattern to copy too.
The coding agents (if we can call the Python Backend that) within is fairly simplistic and predates common modern pattenrs, resulting in some disappointing results.
No feedback loops
While planned, no human freeback tooling or agents existed besides the chat agent wrapper. This is extremely weird given that the goal of arkaine was composable agents - implying a level of complexity and size that would normally encourage some level of human approval/interaction. Sufficiently complex agents should not be assumed to be self sufficient quite yet.
If I had to do it again…
Off the top of my head, and in a manner that is tantalizingly calling to me to really give it another try:
-
Flow should be a natural part of tools/agents, not a separate entity. Separate entities muddy execution flow far too much. Composability should be assumed and streamlined.
-
Composability should be improved to not just be dependent on flow, but also allow inbetween states without a whole new agent. Meaning if I have agents
A,B,CandD, and I want the flow to beAto bothBandC, then the feed the result of both toD, I would in arkaine have many intermediate agents.AtoBandCwould be an agentE, then that agentEtoDwould be yet another agentF. All of these are reported to the user as possible agents, even though it makes no sense to ever exposeEandFas their own things. This gets confusingly complex fast. Agent compositions should allow intermediate states / combinations without having intermediate transitions be standalone agents in terms of tooling. -
The context’s data stores and artifact handling should be far better. Similarly compression techniques when serializing/storing contexts should be exercised to prevent the excessive repetitiveness of contexts.
-
Do not assume local execution - agents should be able to communicate over any interface, thus allowing more easily set up distributed agents. Similarly embrace standards that have come out since such as MCP.
-
Error message overhaul - try and figure out a way to express in a human readable error trace, without overloading the human for long, complex chains - what happened and where, while similarly expressing necessary information on the error.
I’m sure I could come up with a whole host of other changes I’d make, but these along would make for a powerful version 2.
…but will I?
I don’t know. The uncertainty branches from two angles.
Currently my focus is on income generation - for now, that’s the startup HiredCoach. In the future that may mean a job or other projects. arkaine, if I revisit it, will absolutely be a free open sourced framework, so working on it is essentially burning time that could be spent making money and finding a bit more financial stability in a very uncertain and unstable time.
While I had fun building arkaine, I have to ask myself if I would truly enjoy doing a second version when tooling and frameworks have matured across the industry. This is an almost whimsical requirement - will I want to work long hours on a complicated project with no promise of anyone ever using it? I did this time. Maybe I will again. This desire of me can be, at times, mercurial.