GRPO in DeepSeek-R1
tldr
I recently gave a talk at the SDx paper club which I run on the paper DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning. I wanted to take a moment to blog out some of the talk, specifically how their reinforcement learning approach worked.
The recording the day of failed, so this is a rerecording the next morning.
Above is the talk (and here’s the slides) I gave at an SDx paper club. I wanted to take a moment to blog out some of the talk:
GRPO
The models created in the paper both utilized GRPO (Group Relative Policy Optimization - more on that in a bit). This replaces the traditional PPO (Proximal Policy Optimization) used traditionally in RLHF (Reinforcement Learning from Human Feedback), like DPO (Direct Policy Optimization) or its offshoots which favor a direct reward model instead of a learned one.
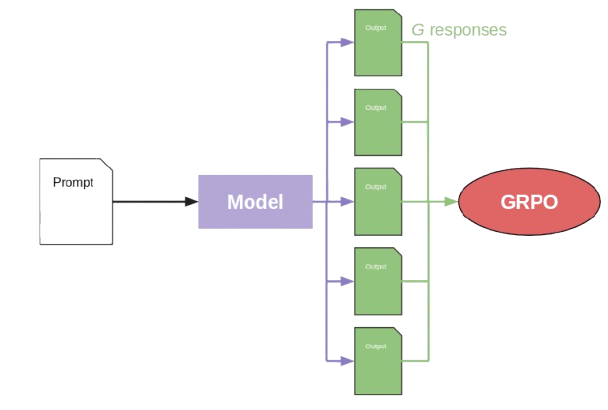
The workflow, boiled down as simple as possible, is to:
- Feed a training prompt into the model for
Gseparate responses (remember the model is stochastic). - Rate each of the produced responses on accuracy (did it answer correctly with reasoning steps) and format (did it reply using the
<think>and<answer>tags). - Calculate the loss via the GRPO objective function.
Let’s breakdown GRPO function itself in more detail. First, the eye glazing blob of math straight from the paper:
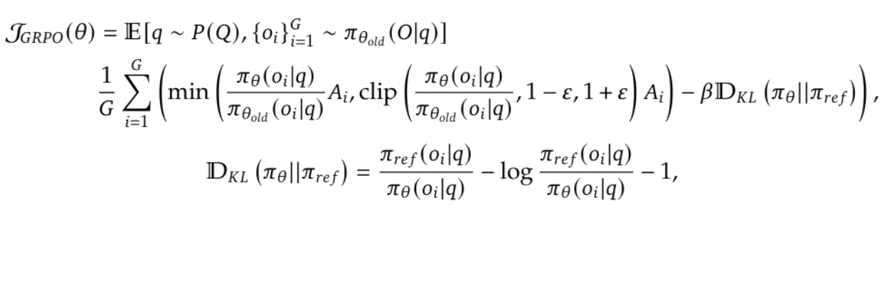
Stephen Hawking once quipped that his editor for A Brief History of Time demanded he remove as many equations as possible because…
[they] told me that each equation I included in the book would halve the sales.
With the large dump of math symbols above, I wouldn’t blame you if you have trouble taking it all in at once. Don’t worry, I’ll break it down piece by piece. Let’s start with the first part; the definition of our objective function for GRPO:
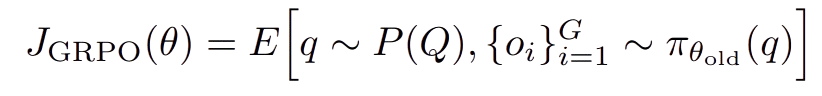
J is a common notation for an objective function - in reinforcement learning it’s what we hope to optimize for. The higher, the better (reinforcement learning is focused on reward, whereas deep learning is focused on loss/error; you can easily swap the two out in your mental models, just remember you’re maximizing or minimizing when appropriate). θ is a common notation of the parameters of our model (the weights for us). E is the expectation operator, which is just a fancy way of saying “take the average over many iteratons”. The ~ is a common notation for sampling from a distribution (remember that our model is stochastic, so it is a distribution). { and } are common notation for a set of items - a collection of sorts. o is our output of the model, and π is a common notation in reforcement learning for the policy being executed.
With this in mind, taken straight from my slides:

So, all together, this says: Sample a query from a collection of prompts creating a set of G outputs using the reference policy then take the average of its scores over many iterations to iteratively improve our weights.
The next bit is just a further definition of our objective function:
$$\frac{1}{G} \sum_{i=1}^G \min \left(\frac{\pi_\theta(o_i|q)}{\pi_{\theta_{old}}(o_i|q)} A_i, \text{clip} \left(\frac{\pi_\theta(o_i|q)}{\pi_{\theta_{old}}(o_i|q)}, 1-\epsilon, 1+\epsilon \right) A_i \right) - \beta D_{KL}(\pi_\theta || \pi_{ref})$$
Wherever we see a Σ in an equation for a set series size then immediately divided by the series size, as we do with G here, you can just read this as “take the average of the series”. min is self explanatory - take the minimum of the values contained within once calculated. clip, the fraction of π’s, and, A are all holdovers from PPO, requiring some background, so let’s talk about that for a second.
One of the key ideas of PPO was a methodology to deal with updating the policy during learning while preventing large updates to the policy. This can be a huge problem when training complex policy models. To do this, the clipping function was utilized to limit the size of the update and discourage big changes, typically to either some calculated value and 1 ± ε (typically some small value like 0.2, but it’s a hyperparameter so it cna be adjusted).
But what about the ratio of π’s? This is a comparison of probabilities - essentially the ratio of probability that the action would occur in the new policy over the probability that the action would occur in the reference policy. This creates a sort of scalar that adjusts the update based on how likely (and thus how important) a given action is to either policy, so improbably rare actions are given less weight.
Finally, the A is advantage. In PPO, we define advantage as:
$$A = \frac{Q_{\pi(s,a)}}{V(s)} $$
…this takes a bit more explaining and reinforcement learning background, but is actually pretty simple. Q in RL means the reward for an action a taken in a given state s, and V is the value function, or how good the given state is expected to be. Or, in other words - how much reward did we score compared to the average reward we would expect to get from that state. Thus advantage can simply be summed to be how much better did we do compared to the average.
In GRPO, there’s no critic model judging the quality of state’s to calculate V (again, check out my prior writings on PPO here and here for a better dive into PPO). We want advantage to still be defined as the improvement over the average, so we change the definition of A a bit to fit our GRPO flow:
$$A_i = \frac{r_i - mean({r_1, r_2, … r_G})}{std({r_1, r_2, … r_G})}$$
Finally, at the end is KL Divergence, a common addition in many objective/loss functions. It acts a measure of how different two distributions are from each other. By subtracting it from the objective function at the end, we are further discouraging large updates to our policy, ensuring that we don’t deviate too much from our reference policy on any individual training step.
So, combining it all together:

Update the strategy based on how much better an action performed compared to the average (advantage). However, it only makes small, careful adjustments (trust region) by clipping the size of the update and discouraging big changes (KL divergence), then averages these adjustments over multiple experiences to find the best overall improvement.
So there you have it - GRPO in a nutshell.