Evolving a Neural Network Traffic Controller
tldr;
I attempted to repeat my success with the evolving race cars by using evolutionary algorithms and neural networks to control simulated traffic flow in a segment of Chicago’s streets. The results were… not so great. You can see associated code here.
What is this?
The tiny ant-like pixels running around above are emulated cars, running through a grid system generated from a rip of a small part of the city of Chicago. A neural network is controlling all of the traffic lights in the simulation. And it likes to cheat. Need more context?
When taking my AI course for my master’s degree, it came time for the final project. The class only lightly touched on deep learning, and while I have the experience in it and a lot of interest in it, we were tasked with picking non deep learning projects. Thinking back to my success with evolutionary algorithms with neural networks in the past, I figured I might as well try it once again but with a more complex domain.
I wanted to specifically avoid having to build out a simulator, so this time our group landed on a few domains that had ready-provided simulations. We landed on traffic simulation via SUMO (Simulation of Urban MObility). It’s utilized in a bunch of research in the space, has a bunch of domain-experts that utilize it, and it had a Python client for controlling it.
There exists a feature to convert maps exported from Google Maps into SUMO-compatible maps. We chose a simpler grid-based city, choosing Chicago (my wife hails from there).
SUMO comes with a set of defaults that is pretty standard for roadway rules. It turns out that there’s some generally agreed upon rules for traffic lights that are pretty performant. By default SUMO would utilize these - so it provided a good baseline to compare to our trained network.
Controlling SUMO
I built out controls for utilizing the SUMO python client to create and control an instance of SUMO. Essentially it was a wrapper class that, given a target map file, would launch SUMO, connect to it, and be able to launch simulation runs with preset configurations. When all was said and done, it could reset the SUMO simulator for the next run or close it down.
The SUMO simulator has a number of artifacts to build the simulation with, but we kept it simple - our streets intersections were each setup with the expected traffic lights for that junction. We added what was called induction loops. These are sensors buried in the pavement near light junctions that can detect the presence and measure the speed of a vehicle traveling over them. These acted as the data input for each of our neural networks we experimented with.
Building the neural nets
Our initial neural network set the phase time of a given light. A phase time in SUMO is the length of time that a light stays at a given phase. Imagine each possible combination of legal lights as an individual phase - not just red, yellow, and green, but also turn signals if needed. The neural network didn’t need to worry about the correct ordering of lights (yellow must proceed red which proceeds green and never moves to red, etc). The last layer of the layer is a sigmoid function, so our output range is (0,1]. This value is translated to a possible range of time values for the given simulation - usually between 3 and 25 seconds (phases couldn’t be 0 seconds).
Thus, for a given map like this, with junctions labeled like J01, containing induction loops of labeled L01_0_0:
…the neural network would be framed like:
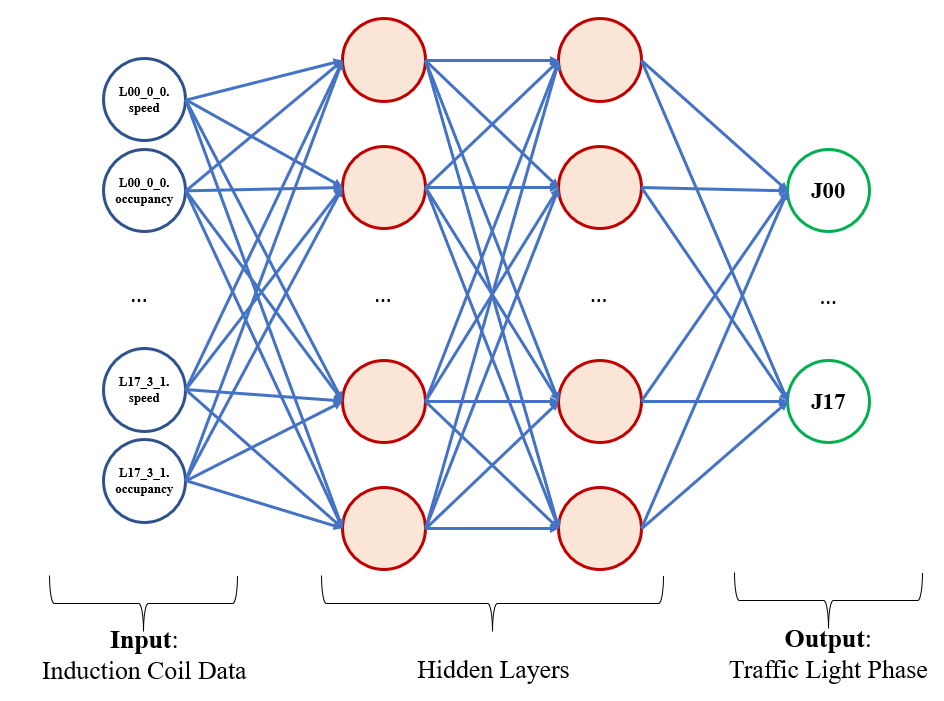
So we now have SUMO asking our neural net for street timings for its city blocks. Now we need to build out the trainer.
The Trainer
In order to train the network we need a fitness function - something from which we can score the network’s performance against. We decided to run the SUMO simulation with a network for a set number of steps (which simulates a set time in real life) and look at one of:
- Total travel time (TTT) (seconds)
- Total depart delay (TDD) (seconds)
- Average Vehicle Speed (AVS) (m/s)
…where TTT was the total time that vehicles traveled through our city, TDD was the amount of time that vehicles sat delayed at lights, and AVS is self explanatory. We primarily used TTT, though we did experiment with the other fitness functions and found little change in performance of our networks after training. The simulation would create vehicles at a predictable rate, so running the same agent multiple times would have different vehicle travel, yes, but running several times would result in similar results.
The trainer would first generate our population if one didn’t exist - essentially a set of N (default 50 for ours) neural networks with randomized weights to start. The trainer would setup a new SUMO simulation for the selected city and run it, querying the phase timers at each step via the neural network. Even though phases would change at each step, our simulator wrapper client wouldn’t apply the timing change until the originally assigned phase was over. A setting, iterations_per, would run multiple iterations of the same neural network on the city and average the resulting fitness scores as the score for that neural network.
Once the entire population had been ran, we compared the scores. A configurable rate of crossover neural networks would be brought over to the new generation unchanged from the prior. Then, until the population is filled, we mate neural networks by pairing them with a weighted probability via their fitness scores; better performing networks are more likely to mate.
Mating between the neural networks would select each neuron weights from one of the two parents at random chance, with a configurable mutation_rate variable on the trainer to pick an entirely new weight.
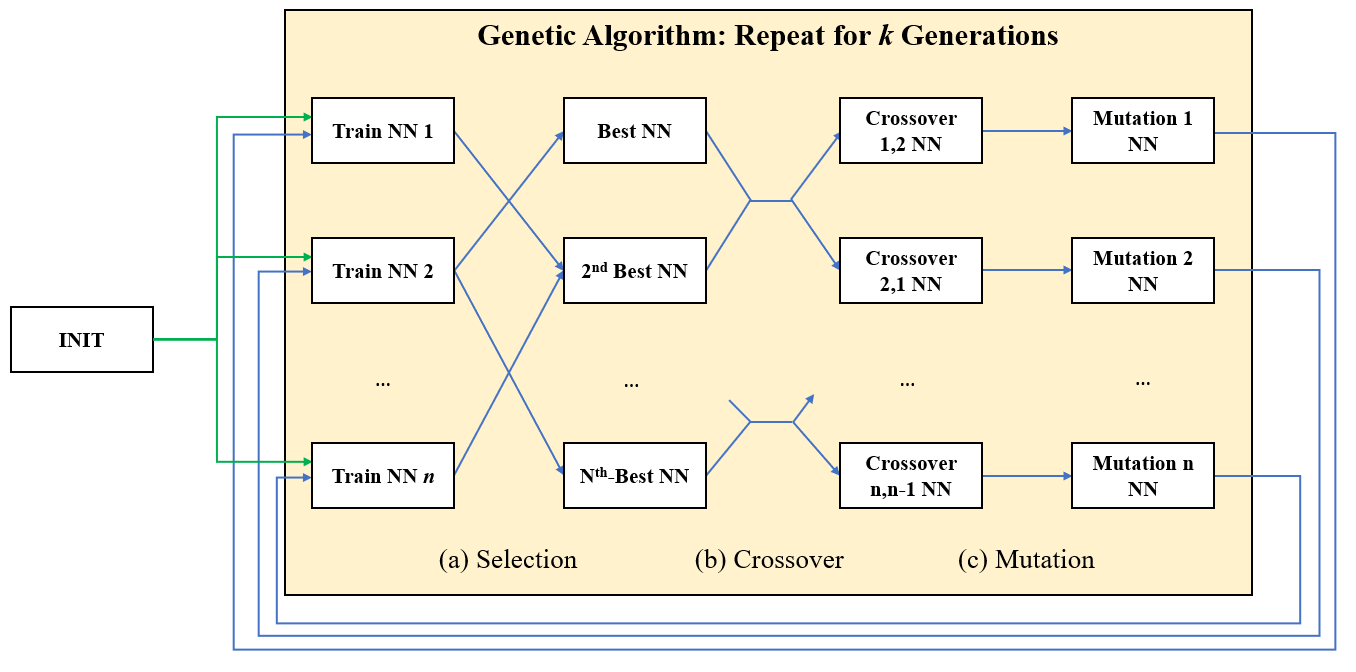
Since running the simulations for the entire population took some time, the trainer also tracks a given neural network’s fitness score between generations if it survives and is brought over; since the neural network and simulation see no changes, its fitness score would be the same and we can avoid running more simulations than needed.
All that was left to let the system train! And train we did for quite some time… only to find that we ended up training a no good dirty cheater.
Cheating
I had left the trainer running overnight once I was happy enough to see that we could run training several generations without bugs or any sudden stoppage. Waking up I was excited to see that the trained agent was already reporting total travel times far lower than the default run-times. My excitement was short lived once I realized what it was doing, however.
It turns out that SUMO has… I hesitate to call this a bug per se. This is more a limit of the simulation as ran by us. You see, at first we didn’t have a minimum time for the length of a light - it could essentially be 0. SUMO vehicles are essentially perfect drivers unless you configure SUMO to demonstrate specific behavior or to allow crashes. We didn’t do this, as our project was already complicated enough that we didn’t want to add additional complexity. Our neural network figured out that if you have an entire city of perfectly polite drivers, you can essentially minimize all traffic lights (essentially making them stop signs) and this libertarian traffic paradise will sort itself out.
Unfortunately for our trainer’s lofty optimism about human behavior, I have driven in Chicago and know that that would never work.
We raised the minimum time to 3 seconds and would watch for this behavior specifically; it never re-appeared once we added the higher minimum phase times.
Initial Results
Cheating “bug” fixed, the trainer ran… and results were never promising. For comparison, I created a random agent and a null agent. The random agent would just choose random phase times always. The null agent would never assign a phase time, instead allowing the SUMO client to use the intelligent defaults common for the streets. The random agent would perform predictably terribly; The random agent had a TTT average of 520,882 seconds. The null agent had a TTT average of 209,994 seconds; a mere 40% of the random agent. And our agent?
A TTT average of 389,471 seconds. Marked improvement over chaos, but not exactly challenging the default timings.
After a week and change of bug hunting, carefully watching what the trainer was doing, trying different features, and trying various sizing in the depth and width of the hidden layers, I couldn’t squeeze any more performance out of it. I decided to try entirely new approaches instead.
More Agents!
First I considered that maybe the instantaneous nature of the network versus its application meant the network was essentially timeshifted from the scale of what its actual effects were. I created two new networks to try to adjust for this. First I created what I called an “Average Agent”; it would track the last several timesteps of data that the networks saw, and then average them together to feed into the network. I also created a “History Agent” - this was a vast expansion of the input of the neural network to just accept the last several timesteps of data instead of instantaneous or averaged data.
Neither of these did much better… a TTT average of 402,713 seconds for our Average Agent, and a TTT average of 398,615 for the History Agent; neither outperformed our original neural network.
At this I decided to try something out of left field.
No Neural Networks
Maybe we can create a set static schedule that would perform well? Instead of using dynamic sensor input from the induction loops, maybe we could evolve a traffic phase timing schedule for each individual junction?
I created a new agent. Simulations using this agent would just be told the same static timing for each phase of each junction on the map repeatedly. Mating across the population would swap out timings for specific timings of a given junction between two parents with a probability, and a mutation rate for a random timing, same as our neural network mating.
I thought this idea had promise. And it did outperform pure chaos, so we had that going for us. This agent had a TTT average of 402,572 seconds… right in line with the Average and History agents.
Lessons Learned
After a lot of work we called it; you can check out the paper here which goes into a bit more depth of what I discussed here. To no one’s surprise, we didn’t produce better results than default settings by domain experts, but we did show that you could get some decent results with evolved neural networks.
If I was to do this again, I would probably use more reinforcement learning than just an evolutionary approach. I also would try to parallelize SUMO somehow; its nature forced us to run one simulation at a time. Even with a decently powerful computer running it, ten generations of a population of ten networks took 10 hours! Experiments were slow to get results and iteration was a crawl because of it. This is a lesson I’d learn again in the future with some reinforcement learning projects.
I know I’m a bit more patient at traffic lights now.