Utilizing LLMs as a Task Planning Agent for Robotics
tl;dr
For my Master’s capstone project, I demonstrated that not only can LLMs be used to drive robotic task planning for complex tasks given a set of natural language objectives, but also demonstrate some contextual understanding that goes beyond information known about the world state.
Just want to see the result? Jump to here. Just the code? Here.
- Introduction
- ROS2 + the Robot
- Initial Mapping
- Action Primitives and Execution
- Task Planning
- Demos
- Results
- So is this a big deal?
- Next Steps
- Discussion
Introduction
When I posted my compilation of the latest research of LLM agents and their applications to robotics, I alluded to my upcoming project that would make use of some of the techniques. I spent the last two months of the year deep in Python and ROS2’s innards for my Master’s capstone project. The goal - use LLMs to control a robot for home tasks; specifically item fetch tasks for simplicity. The project is now complete, and while some of the more ambitious goals had to be reeled back due to deadlines, I’m still happy with the outcome. It demonstrated something I’ve been hoping to prove for the past year - that LLMs can not only be used to create task plans for long horizon tasks, but also provide some contextual understanding that enhances its planning. I’ll be using this project as a springboard for future projects.
While rough (in rushed academic project fashion), all code available for the project can be found here which includes instructions on how to build and run.
Herein I’ll be describing the core robot setup, internal systems (such as navigation, movement, vision for updating state, and how interaction is handled), and finally explaining how LLMs were utilized to create task plans for a given objective. Feel free to jump around to the section that interests you - it’s a long one to read straight through.
ROS2 + the Robot
I did not want to spend my time on this project creating a custom simulation or emulation, like I did when I was creating a simulated urban delivery robot for a global + local planner project, or a dozen other projects throughout the Master’s.
Similarly, I wanted to ensure that I got a project with ROS or ROS2 under my belt. I’ve read books, did tutorials, and took some courses to get myself up to speed with it; but I wanted to get hands on experience in a more realistic project in it to cement my understanding of it… and of course give me confidence to say on my resume that I can work in ROS/ROS2 comfortably.
ROS2
The most recent version of ROS2 at time of the project was Iron Irwini (iron) but compatibility for a number of packages was an issue, as it had just been released; so Humble Hawksbill (humble) was utilized instead. I wrote extensively about my experiments with repeatable ROS2 developments in preparation for this project, so to understand my setup in depth I’d suggest looking there first. The tl;dr - VM and Docker wrapping of environments with just as a task runner to keep life simple. Otherwise a normal ROS2 setup.

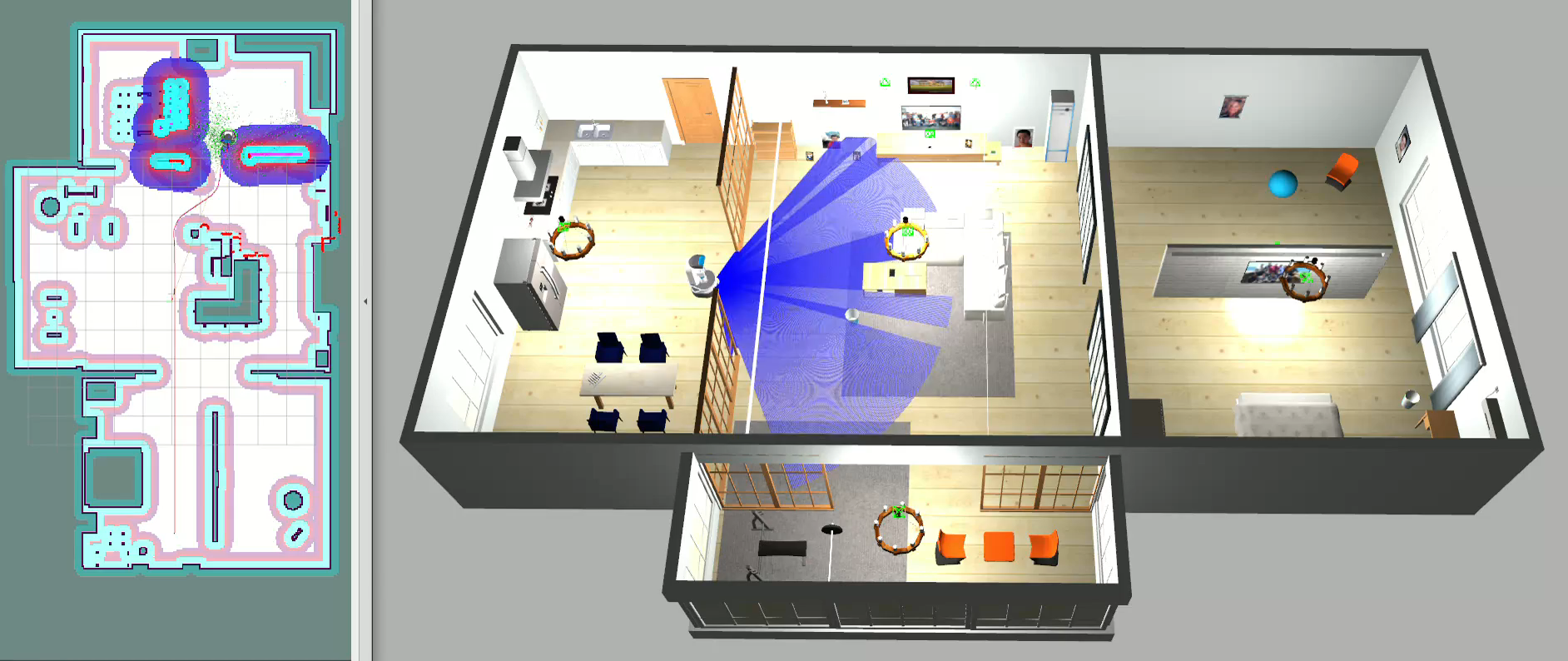
The project uses the TurtleBot4 as the target robot. This worked, but originally I hoped to use a more “realistic” robot that could solve the tasks put in front of it. Efforts to get a robot with an arm manipulator were made, but issues arose. Specifically, we used a URDF model for the Fetch robot since models were readily available and having an arm made sense given the target task. Unfortunately time ran out and inertial issues with the model causing massive drift in its IMU was not fixable, so we stuck with the TurtleBot4.

You can see our navigation issues exemplified here:
To handle navigation, navigation2 and cartographer modules are used. This took some configuration but was thankfully straightforward.
litterbug - handling interaction
The primary focus of the project was the task planner; with hard deadlines in place some aspects had to be simplified. What wasn’t desirable or wise was to be bogged down trying to get a robotic gripper to reliably work within a simulation. Interaction obviously had to be mocked out or simplified drastically within the simulation to make things doable in the allotted time frame.
With this in mind, it became clear that we would need a service that was aware of what items were in the simulation, track them, and remove them from the environment when the robot “grasped” them up. Enter the litterbug service. The original goals of litterbug were:
- Given a
csvof items, spawn them in the simulation at initialization, tracking them throughout the runtime. - Handle calls to pick up an object or give it to the human - and by extension remember the robot’s “inventory”.
litterbug was made aware of the robot’s position, and utilized a number of Gazebo plugins to take additional control of it. On that front we needed the following paths enabled:
/spawn_entity- to spawn items in the simulation/delete_entity- to remove items from the simulation/gazebo/get_entity_state- to get the state of an item in the simulation, its location (since the robot can bump things and move them) and to confirm if it exists prior to other operations/gazebo/get_model_list- to get a list of all existing models in the simulation
To get these working, you have to enable specific Gazebo plugins, which can be done by adding the following xml to your world file:
<plugin name="gazebo_ros_state" filename="libgazebo_ros_state.so">
<ros>
<namespace>/gazebo</namespace>
</ros>
<update_rate>1.0</update_rate>
</plugin>
<plugin name="gazebo_ros_factory" filename="libgazebo_ros_factory.so">
<ros>
<namespace>/gazebo</namespace>
</ros>
<update_rate>1.0</update_rate>
</plugin>
<plugin name="gazebo_ros_properties" filename="libgazebo_ros_properties.so">
<ros>
<namespace>/gazebo</namespace>
</ros>
<update_rate>1.0</update_rate>
</plugin>
litterbug created a service for picking up objects and giving them to the human. Picking up an object checked to see if the robot was within a set distance of the object; if it was, it succeeded; otherwise it reported a failure. Giving an object to the human would check to see if the object was in the robot’s virtual inventory, and if the robot was within a set distance to the human.
State Tracking
Our LLM agent needs some representation of the state of the world, so we need to convert our current world state as best as possible to text. The state service tracks the existence of rooms and items and their relative position to the robot, while providing several ways to query the items for generating the appropriate items given the robot’s task.
The service starts by listening to the /objects_spotted ROS topic, wherein the vision system can alert a possible x/y coordinate location of an object with a known label. To avoid possible one-off false positive reportings, the service waits until a set number of reports come in, raising confidence that the object is there. Since the positions of the items have uncertainty, an averaging of the past (up to) 100 reports are performed, slightly adjusting the location and zeroing in on its probable true location. Items with equivalent labels are considered likely to be the same exact object if they are within a set distance of each other (a few centimeters).
Items are labeled with a simple numerical ID (this is simpler for the LLM agents to directly refer to them as 1 or 2 versus longer complex UUIDs). Your typical CRUD functions are implemented for typical management and direct recall. Similarly, querying by room label is also available (I want all items in the bathroom, for instance)
When querying items, an additional endpoint in the service provided vector embeddings as a search solution. Given the query - usually the objective itself - we can generate a vector representing the query and determine the closest objects per the cosine similarity of two vectors. This allows us to query for objects we know about despite an indirect reference; i.e. coke and a beer is a drink, pills and drugs maps to medicine well, etc.
All of this is served up in a standalone service and data is maintained in a SQLite database for persistence.
Vision - Real + Simulated
…speaking of vision, we need the robot to recognize what’s around it. YOLOv8 was chosen as a readily available, easy solution that could find bounding boxes for a set of labels, with datasets already capable of detecting objects we’d expect to find in our simulated house.
YOLO detects objects in bounding boxes, giving us the corners of the bounding box. To convert this to an estimated (x,y) coordinate in the real world frame, we’d first calculate centroid of the bounding box. Since we’re using a depth camera, we then can take the depth value at that calculated centroid coordinates as an additional axis for our z axis. We convert the location to the real world frame by moving through kinematic frames - our camera to our base link and then to the world frame. The result is a rough but useful approximation of the real world location of the item.
This feature worked but arrived late, and it was unclear if it would work reliably enough to be used in the project. To ensure there was a backup for this I developed a simulated vision system. Since the aforementioned litterbug service was already tracking robot pose and had omniscient tracking of all objects in the simulation, I expanded its responsibilities to also allow for the simulation of vision. How?
litterbug considers the current position of the robot and then notes its internal listing of all objects, filtering for all items within a set radius (our vision range, approximately 8 meters). Once filtered, it then determines if the object is within the field of view (FoV) of the robot by checking the current heading of the robot versus the item’s angle relative to the robot’s position; if it falls within a certain angular FoV, it can still be possibly seen. We then referenced our original occupancy map generated by mapping the environment. A line is drawn between the robot’s centroid and the item with Bresenham’s algorithm across occupancy map; if any obstacles (i.e. walls) are detected, the line of sight is blocked. Finally, based on the range of the object to the robot, there is a probability of not notifying the robot of the object to simulate a false negative. When the location is finally broadcasted, the location has random noise added to each axis to signify realistic uncertainty of location.
You can see this code specifically in __within_cone and vision_check within litterbug.py. It emulated a camera at approximately 24 FPS.
Initial Mapping
To navigate around the house, the robot needs a map of the environment. We also want to build an initial understanding of the environment - what items does the house contain? What rooms are there, and where are they located? To start, the robot is situated in the environment and told to perform an initial mapping of the environment. Once we’re done mapping we have some additional processing to try and extract more information about our environment to empower future tasks within.
Exploration
Our goal is to map out the environment; but how did I do this? We utilized navigation2 and cartographer packages to create our map and move around, but how did the robot decide where to go for its exploration? A simple exploration service - explorer - was created. The service’s aim was to track the current state of its compiled world map, and then determine the best spot for the robot to go to continue its exploration.
The explorer service subscribed to /odom and /map to get the robot’s current position and its most up-to-date version of the world map in the form of an OccupancyMap; an array where coordinates map to -1 for unknown, 1 for a known obstacle, and 0 for empty space.
explorer would, at a set interval (approximately every 5 seconds), take the latest broadcasted OccupancyMap and perform a simple A* search to find the best possible spot to continue its environment discovery. How to choose the “best” spot became a key matter in reliable performance. Below we’ll look at some examples of the feature as it was being developed. As a debugging aid I added a feature to output the map at search-time as an image. I’ve strung these together as gifs, but made a crucial mistake that mars some of them; the map grows over time, so the image size does too. Thus you’ll see some weird artifacts as the map changes sizes in the images which can be safely ignored. The blue pixels are considered locations - our search space. The green pixel is our robot’s current location, and the red space is the ultimately chosen goal location for that search.
The first version was simple - find unknown squares some set distance away from obstacle pixels.
Here we see my first problem; unexplored pixels allow the agent’s search to snake outside the bounds of our test environment. The robot becomes obsessed with targeting these unreachable spots as its next goal, which causes it to become stuck forever. After this, an additional rule was added to limit our choice of spots only to those adjacent to an already discovered known spot.
This worked great on the simpler test environment, but encountered some issues in a more complex and realistic environment. In this Gazebo sample home, the robot successfully explored some of the rooms, but became obsessed with an unknown pixel inside the middle of a trash can. It would repeatedly try to reach it, but the robot’s size prevented it from getting around the edge of the trash can to see it was a solid object. Here’s the overhead shot of the world and the offending trash can:
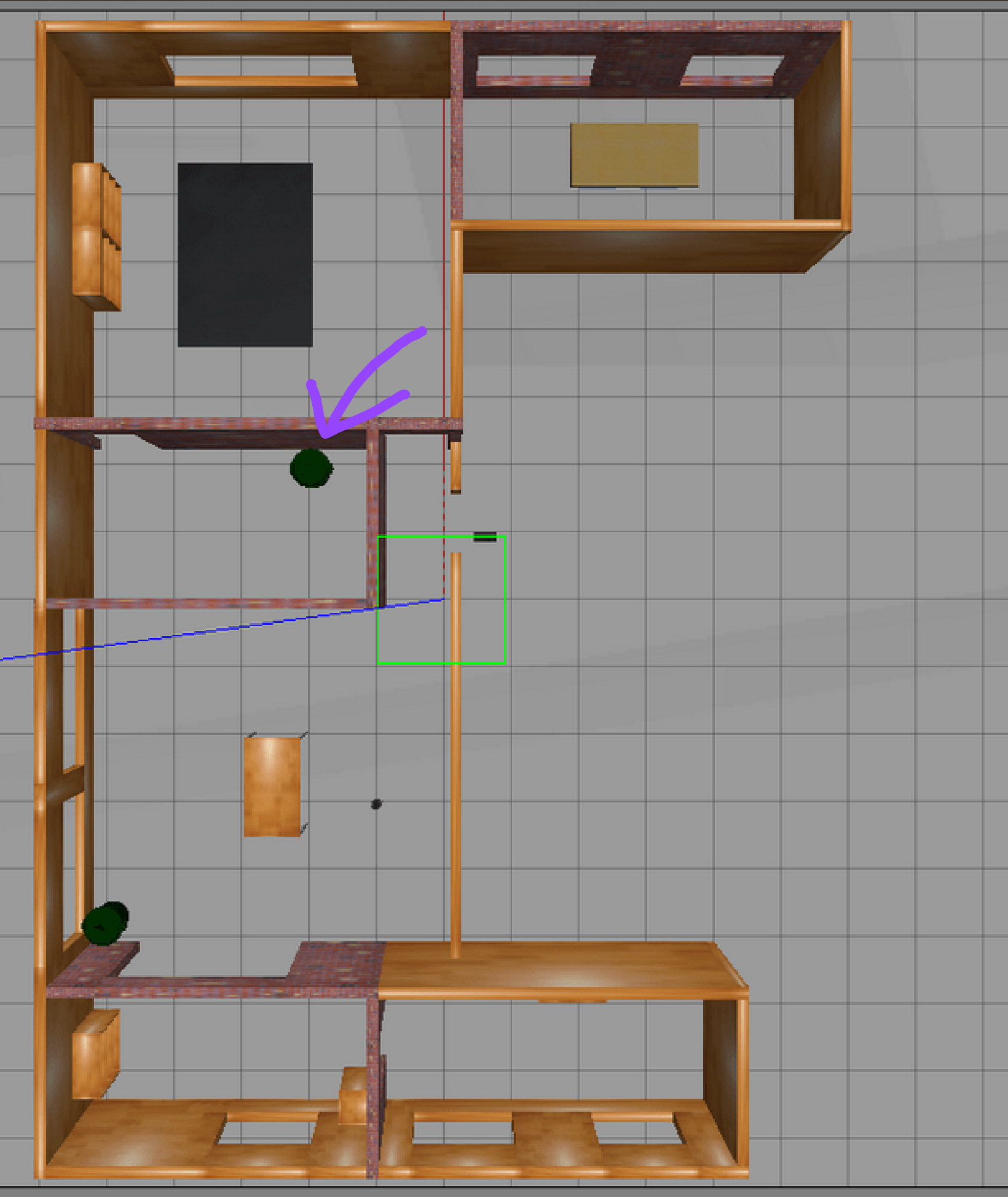
…and the problematic search:
This spawned a few additional features to try and improve selection. The first was __check_chonk_radius, an internal check that, when given a set of coordinates for the given map, would determine if the robot’s radius would fit within the empty space; a rudimentary collision detector. If not we couldn’t consider the spot, preventing us from becoming obsessed with impassable spaces.
Speaking of becoming obsessed, it would be best if a robot did not become focused on a singular spot. All spots recommended by the search are noted; anything that is repeatedly recommended within a set range is added to an ignore list. No spot within a set distance of a spot in the ignore list is considered as a viable goal.
To raise the cost of “escaping” out of bounds due to unknown pixel coordinates allowing the searcher to snake out and consider out of bounds locations as possible goals, the heuristic cost for the A* search was modified from direct distance from the robot to total distance traveled; snakier paths would be more expensive than direct ones. This also is why the earlier examples show radial search patterns and the latter ones seem more pixelated in its search.
The next feature was to create a copy of our map that removed all obstacles, then apply a convolutional filter with a set kernel of 1’s and save it as a separate map. This essentially creates a rating on each pixel coordinate for how many unknown squares are near it. A lower rating is desirable for our search, so we could rank possible locations with this and filter out sparse one-off unknown pixels.
The next feature was to do the same, but instead of ignoring obstacles and filtering on unknown squares, we ignored unknown squares and filtered on obstacles. This created a map that rated each individual pixel coordinate with a rating of how close it was to other obstacles; high values were less desirable as it created collision risks, so we could filter out these locations as well.
Here’s the filtered map code, which is a part of our larger search class with all other mentioned features.
def __process_maps(self):
"""
Given our initial map, we are now going to filter our map
with kernels to try and detect large clusters of unknown
spots. This is done to prevent small individual hard-to-reach
unknown spots from dominating our search.
We then use the same technique to generate a "obstacle"
proximity map, wherein we rate how close certain cells are to
obstacles. This is to fight against the explorer honing in on
cells that are *just* beyond the walls as a target location.
"""
unknown_map = np.copy(self.map)
obstacle_map = np.copy(self.map)
# We have a map of 0's, -1's, and 1's. To detect the cluster of
# -1's, we will go through each spot in the map and add in the
# kernel size's surrounding pixels to the current pixel. Thus
# lower values will be more unknown, and higher values will be
# more known. First, however, we will convert our known empty
# and known occupied spots to 0 for this calculation.
clustered = unknown_map.copy()
np.where(clustered == OCCUPIED, 0, clustered)
# Now we perform an operation on each cell adding the surrounding
# kernel sized cells to its value.
kernel = np.ones((self.kernel_size, self.kernel_size)).astype(np.float32)
filtered = cv2.filter2D(clustered.astype(np.float32), -1, kernel)
self.__unknown_map = filtered
# Now we will do the same process for the obstacle map; we will
# be ignoring the unknown squares though
clustered = obstacle_map.copy()
np.where(clustered == UNKNOWN, 0, clustered)
filtered = cv2.filter2D(clustered.astype(np.float32), -1, kernel)
self.__obstacle_map = filtered
All of these additions made a successful exploration service to power room discovery. While this ran, items would be viewed and recorded for future task-focused runs.
Room Segmentation and Labeling
We have our map generated, and also took note of items during that process. As part of providing state context to the LLM agents, we wanted to provide information about what rooms were known about, and what items belonged to what room. This raised the question - how do we determine what room a given location is in?
To solve this, a classical computer vision pipeline (no deep learning) was created. There’s a lot of interesting research on the subject of room segmentation; the state of the art primarily focused on trained deep learning models. This would be my first choice as well, but time was severely limited; there wasn’t nearly enough to generate a dataset large enough to achieve decent results. A more manual classical CV approach was required.
And those first efforts? Let’s try it against the occupancy map of the old Willow Garage offices:
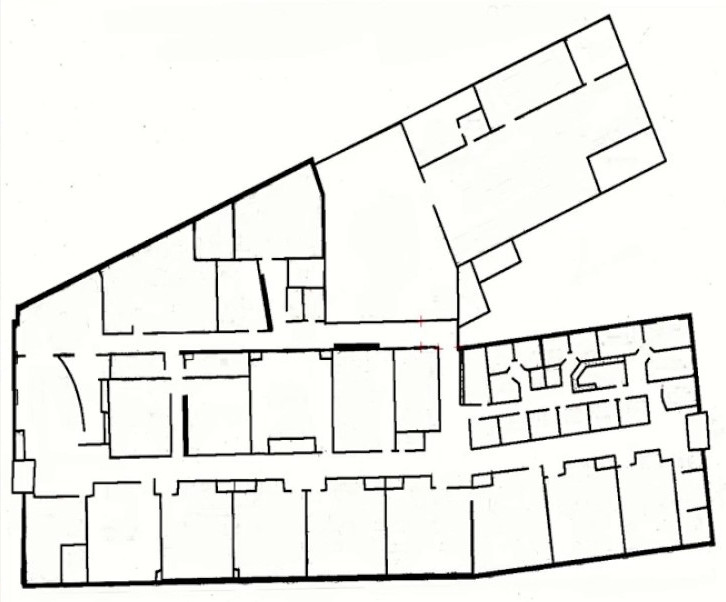
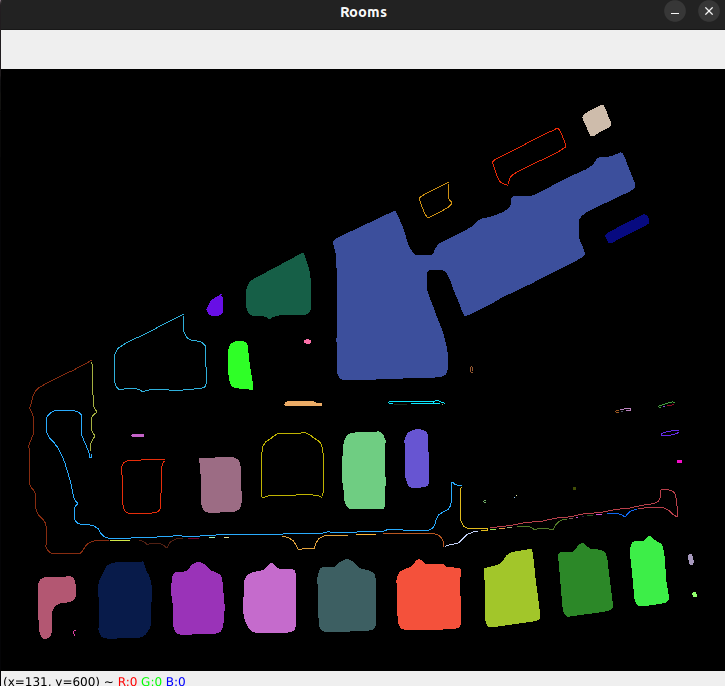
This was clearly less than ideal. The contours were not creating compelte shapes, I was losing most of the rooms, and some of the rooms detected only picked up the outline of the room for very weird area segmentation. I experimented with some additional work trying to isolate rooms with morphological openings (erosions followed by dilations) and distance thresholding. The results were a bit better, but still not ideal. Especially with the thick borders around segmented rooms.
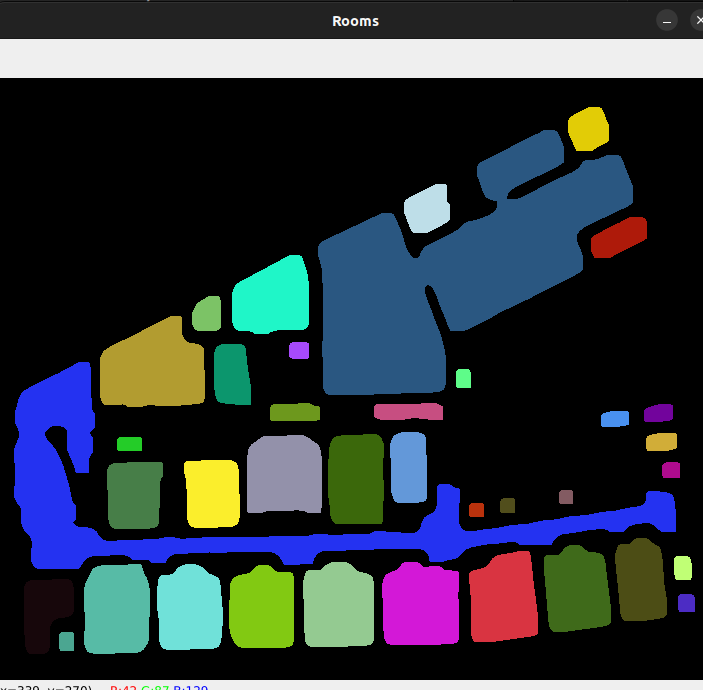
After doing some additional research, I found some papers that utilized the watershed algorithm and it had built in support with OpenCV. It still took experimentation to fine tune for my setup, but results were promising.
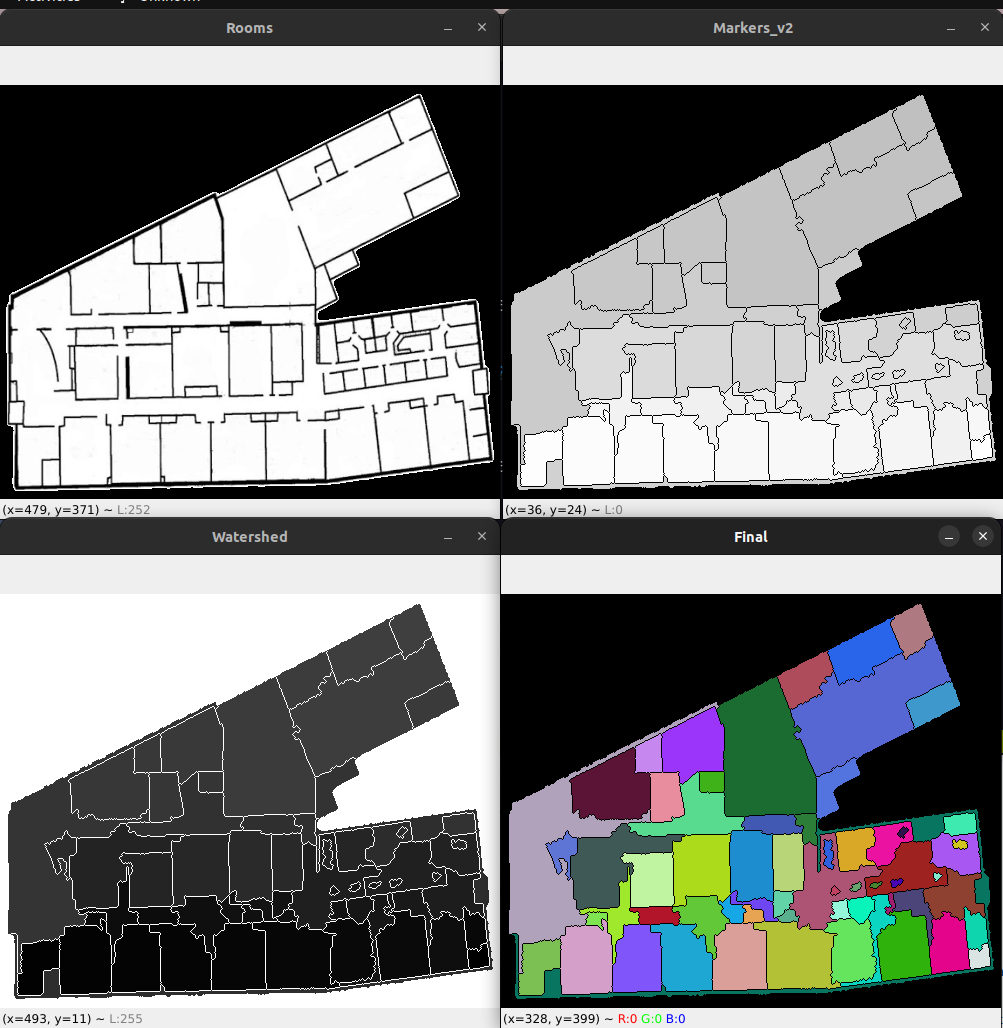
By this time the actual target apartment was ready, and I continued to iterate on the pipeline configuration, adding in a few more features. Things like detecting when a segmented room was below a configurable area (such as a zone a couch would make in the middle of a room) and then having it adopt the surrounding room’s label. Here’s an example of the finished pipeline running through our map; from original image to isolated and blurred image, to distance thresholded:

…and the final outcome:
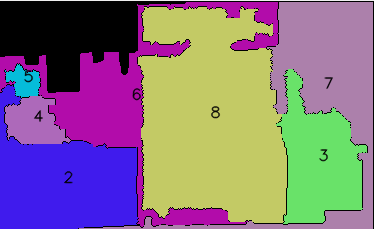
Not perfect, but good enough for our purposes, especially with time constraints.
Now that we have the occupancy map converted to per-pixel segmentation, we collect a list of all the spotted items during the exploration run by querying our state service. We convert each estimated location of the object and then compare that location to its segmented label on the map. By the end of this we have every object grouped by its room label.
We then ask an LLM - “Given the following items, what would we label this room?". After all, if we were to drop a human into a random household room, they’d be easily able to identify it from its contents. A bed and dresser? It’s a bedroom. Couch and TV? Living room. Toilet and shower? Bathroom. No one has an oven in their bedroom (I’ve had a studio apartment, so yes, I understand this isn’t technically true, but work with me here). This label is important - if we do not know where an item can be, we can use contextual clues to guess where it might be. If you were teleported to a random house and asked to find a toothbrush, you’d have a pretty good idea of where it’ll be.
Once labeled, each item’s listing is expanded with that room label for easier grouping; similarly, the centroid of the room is calculated and added to the state service, as well as the generated segmentation map. The state service exposes two new ROS services that will, on request, tell you the given centroid of a room (for generically moving to it), and can tell you what room a given coordinate location is in. It also uses the map internally to label newly detected items with the appropriate room label.
The code for this pipeline can be found here.
Action Primitives and Execution
The underlying components making up our robot are usable, waiting to be controlled by code. The next step is to create a set of action primitives - small building blocks of minimal robot behaviors - that we can use to build more complex behavior; bite sized features that can be readily explain to the LLM-powered agent. Since the LLM agent acts primarily through text, how can we translate its output into actionable robotic control?
Encapsulated Actions
My first thought was to have the robot generate some code-esque output and write my own parser. It didn’t take long to have an initial setup working; I encouraged the LLM to generate a set of code with a comment before each line, and then the next line use a “function call” a-la text that followed the pattern of function(parameter, parameter, etc). This worked, but then I realized I probably needed looping, and maybe conditional branching. Then I realized I’m essentially reinventing the wheel and writing a language parser. That sounds like a great way to burn way more time than I have. I also realized that I might be able to get the LLM to stick to a simple vocabulary for its output, but as the tasks got more complex and the available syntax expanded, I would run into an issue where the LLM would likely assume that my output was Python and extrapolate from there, utilizing language features I simply didn’t anticipate or build.
Eventually I came to the decision that I had to embrace the impossibly large troves of Python training data LLMs are trained on and just use Python code as the target output of task plans. This brought with it a different set of issues, however.
How can I safely execute Python code? Also, ROS2 is a distributed system with concepts of cancellation, messages, interrupts, and more in the background; how can I safely stop in the middle of plan execution if needed? How do I deal with incoming vision data coming in asynchronously of the task plan? I want to do all of this while keeping the code simple enough that I can succinctly explain to the LLM how to utilize each function.
Actions
I created an Action abstract class to handle much of this. The goal of the Action object was to encapsulate functionality around asynchronous cancellation and result assignment. For example; if the action primitive moved the robot, this could be cancelled for a multitude of reasons unbeknownst to the planner. Similarly, a result that the action might be looking for - such as whether or not something is spotted during recent movement - could come in on another channel at an unknown moment and needs to be reported safely, in a manner that the synchronous simpler code of the task planner is blissfully ignorant of.
Each function could extend the class and drop into a generic handler that executed the code (which I named the ActionPlanner, code here) that maps the resulting actions to function names within a set of generated code. Next was creating a set of “small” actions that could be imagined as composable to more complex tasks.
The language
With the actions ready to be utilized, I needed to build out the syntax I’d expect the LLM to utilize. The following is not only the functions the LLM is armed with, but the also the exact wording used to inform it of its functions in its prompt:
move_to_object(object)→(bool, str)- This either accepts a label of an object or an id of a specific object. If we know about the object the robot will move towards it. If we do not, it will immediately fail with
(False, "item not known"). If it fails to reach the object, it will return with(False, "D away from goal")whereDis the distance in meters from the specified goal. It will also fail if the robot completed the trip but does not see the item when arriving with(False, "object not seen"). On a success it will return(True, ""). move_to_room(room)→(bool, str)- Given the name to a room you know about (ie, “kitchen”), this will navigate you to the center of that room or as close as it can. Do not navigate to rooms you do not know about. On a success it will return
(True, ""), and on a failure it will return(False, "D away from goal"), whereDis the distance from the goal in meters. move_to_human()→(bool, str)- This function will move you to the last known location of the human. On a success it will return
(True, ""), and on a failure it will return(False, "D away from goal"), whereDis the distance from the goal in meters. pickup_object(object)→bool- Accepts either a label of an object or an id of a specific object. If the object is within 1.0 meter of the robot, it will pick it up. Returns
Trueon a success andFalseif the item is not present. give_object(object)→bool- Accepts either a label of an object or an id of a specific object. If the robot is within 1.0 meter of a human and has previously picked up the object, it will give the object to the human. Returns
Trueon a success andFalseif the item is not present. do_i_see(object)→bool- Given a label of an object, this returns whether or not the robot has seen this object within 8.0 meters of it within the past 5 seconds.
look_around_for(object)orlook_around_for([object, object, ...])→[(label: str, distance: float)]- Given a label of an object or a list of objects, this function will cause the robot to spin in place, looking for the specific object. If it finds an object, it will return the
[(label: str)]of the found object(s), and[]if nothing is found complete()- Return this when you are done with the action, and the action is successful
fail()- Return this when you are done with the action and have hit a fail state
The implementation for each of these functions can be found here; each extending our base Action class described above.
Few-shot demonstration
A few-shot approach was taken; three simple examples were provided after describing the functions themselves, each instructing the agent to wrap their function in a run() function and call it. A sample of the type of example provided in the prompt:
def run():
# Move to the object
print("I am moving to the object")
success, msg = move_to_object(13)
# Abort if we failed
if not success:
print(f"Failed due to {msg}")
return fail()
# Pickup the object
print("Picking up the object...")
success = pickup_object(13)
if not success:
print("Could not pick up item :-(")
return fail()
# We need to bring the item back to our user
print("I have the object; I am taking it to my user")
success, msg = move_to_human()
if not success:
print("Could not navigate to human")
return fail()
# Give the human the object
print("giving the user the object")
success = give_object(13)
return complete() if success else fail()
run()
The examples not only demonstrated printing and commenting its reasoning first, but also encouraged through instruction to express itself:
Whenever you generate code, write comments before each section to express what you’re aiming to accomplish. Use print statements liberally to describe your thought process and actions to share with the user what you’re doing.
This is not just done to create a faux personality to interact with our user; it has been shown that outputting the reasoning prior to the output increases performance across complex tasks.
Isolation
When we execute the code, we’re essentially telling our LLM to take the wheel and giving it complete control of our robot (and its computer) during its task plan execution. This is a bit on par with just running any ol' code or terminal commands you copy and pasted off of the internet.
I considered two possible routes; containerization and a limited pythonic language.
I could create a Docker container for the generated task plan, complete with required tooling, and execute it there. This would succeed in isolating network and file system access. This introduces a few problems; namely memory sharing. It would become quite an ordeal to safely share application memory between the container and the ActionPlanner. This is adding a significant amount of complexity to a project that, by now should be clear, had a strict due date.
I then considered Starlark. Starlark is a pythonic language that can not access the file system or network without an external module granting it. You can inject functionality for such access into the runtime of the Starlark script to gain controlled access as needed. I’ve used Starlark before; specifically through Go for safe script execution on remote robots and function-as-a-service deployments. Unfortunately this is a Python based project, and pystarlark, the only implementation I could find, seemed abandoned and wouldn’t install. I’ve since found starlark-go as a Go dependent Python implementation of Starlark, but didn’t know of it at the time of building this project.
With time counting down, I decided to try the more dangerous route of just running of the raw code. I never ran into any issue, but this is definitely a worrisome point if you want to run generated code on your machine. If I were to do this again, or was generating more complicated code, I’d definitely take the Starlark approach.
Execution
With all of this written, it was time to run the code. At execution time the code is taken as a string, and a global memory dict is created with function names pointing towards lambda wrapped Actions we created earlier. Finally, we use exec to execute the code.
def execute(self, code: str):
"""
execute will begin executing the plan, blocking until the
plan is complete or errors out.
"""
# First we need to check the syntax prior to executing
self.code_check(code)
# If we reach this point, the code is fine and can continue and
# attempt to execute the code as written
try:
# Create a series of lambdas that create new Actions
# when a given action is generated
globals = self.__generate_lambdas()
# Expand our wrapped actions with the provided functions
functions = self.__wrap_functions()
globals.update(functions)
locals = {}
exec(code, globals, locals)
except CancellationTriggeredException:
# If the cancellation is triggered then we can simply
# return at this point - there is no additional work
# to do.
return
except Exception as e:
# Record the error and raise it
self.__set_error(e)
raise e
The lambda wrapping was to convert our Action objects to callable functions and provide some additional niceties. Specifically - allowing an on call hook to be added in, so we could broadcast out the current action being executed and its parameters, track our progress across the code body, and so on.
def __generate_lambdas(self) -> Dict[str, Callable]:
"""
__generate_lambdas creates a set of lambda functions to be passed
into the code that wraps it with __action_wrapper, where the action
object is cloned, set as the current object for tracking and
cancellation, and then executed as called.
"""
lambdas: Dict[str, Callable] = {}
for function_name, action in self.actions.items():
lambdas[function_name] = partial(self.__action_wrapper, function_name)
return lambdas
def __action_wrapper(self, function_name: str, *args, **kwargs) -> Callable:
"""
__action_wrapper generates the action clone for the specified action,
saves it as the current action, and then executes it, returning the
resulting outcome.
"""
if self.__on_call_callback is not None:
self.__on_call_callback(function_name, *args, **kwargs)
# First we create a new action of the specific type
action = self.actions[function_name].clone()
# Set this as our target action
with self.__action_lock:
self.__current_action = action
# Execute the action
return action.execute(*args, **kwargs)
Buffering
I wanted the robot to interact a bit more with the user, and thought print statements were a fun way to try to extract the robot’s reasoning. To do this I used a trick to redirect STDOUT to a buffer for broadcasting.
At the point of execution within the engine:
out = StdOutRedirect(self.__broadcast)
with redirect_stdout(out):
self.__action_planner.execute(code)
sleep(0.25)
…and the redirection buffer:
class StdOutRedirect(io.TextIOBase):
"""
StdOutRedirect will send all writes to stdout
to the provided callback.
"""
def __init__(self, target: Callable):
self.target = target
def write(self, s: str):
self.target(s)
…which allowed me to create functions that hooked into the StdOut buffer. I broadcasted it on a ROS topic of objective/ai/out.
The fun part was later I created an ai_streamer app that would listen to all relevant topic broadcasts and print it out for easy tracking of our distributed AI and robotic system. The objective, triggering of robot functions, and anything printed out on objective/ai/out shows up here. I also added in voices via ElevenLabs, which gave demos a touch of personality…
…and some childish glee on my part.
Task Planning
At this point, the action primitives and functions are designed; we can convert a generated set of Python code and execute on our robot… so how do we generate the plan itself?
I prompt the agent with the following:
You are an AI that produces a set of python code utilizing special functions to control a robot. Your goal is to complete the given objective using python code and these functions. Do not use functions not provided to you unless it is available in a base python environment.
…and follow it up with the functions prompt and some examples, discussed earlier. We need to give the agent a sense of the world in its context window. We query the state service for a list of all rooms we know about, and then provide the distance of the robot from the center of each room. We take the objective and utilize the aforementioned vector embedding search to isolate items in state memory that are somehow related to the objective. This list is correlated by room, letting the agent know not only how far was the item the last time we saw it, but also what room it was in. It may no longer be there, but it gives the robot a sense of what might exist as it searches. If none of the items are useful matches, the agent can still utilize the room labels as key information.
The agent is finally given the mission objective and asked to generate a plan. We produce multiple plans in parallel (5 for our purposes).
I found that despite being told to only produce Python, all of the LLMs utilized would often write additional text and wrap the Python in Markdown ```python tags. I gave in and just wrote a parser that would detect if such tags existed and isolate the code within.
Rating
How do we determine which of the plans are best? We can start by quickly spot checking them by via a syntax check; anything that isn’t proper Python code won’t be considered since it can’t run anyway. An additional spot check is done to ensure that we have at least some of our robot functions in the text body; an absence of them implies the code does nothing.
The next stage of ranking the code is a bit more abstract; we need to spot check if the logic encoded makes sense given the information presented. An LLM agent is prompted with the functions, state prompt, and each generated plan. It is asked the following:
You are a AI controlling a robot through python code with a set of special control functions. You are going to be presented with a set of python code “plans” identified by an integer ID. to accomplish a set objective. You are to reply with a JSON response that rates which plans are best by assigning a score and explain your reasoning. A 5 is excellent, a 1 is terrible. Always write your reasoning first. Your response will look like the following:
{
"results":
[
{ "reason": "This plan attempts to move to the snack we last saw in the living room, and, failing that, goes to the kitchen which makes sense", "plan": 0, "score": 3 },
{ "reason": "This plan moves through every room methodically, but will be much slower than other rooms.", "plan": 1, "score": 2},
{ "reason": "This plan moves only to the bathroom, where the robot is unlikely to find food", "plan": 2, "score": 1},
{ "reason": "This plan succinctly accomplishes the goal by immediately moving to the kitchen - the likeliest place to get food - and grabbing the requested item.", "plan": 3, "score": 5},
]
}
Does this work? Kind of. I think this is one of the primary weaknesses of the approach; time was too limited to do significant prompt engineering, build up a dataset of plans for possible fine tuning, or experiment with alternative multi-shot prompts.
So if I’m not completely sold on the LLM’s ability to reliably rate the plans, but think it generally can accomplish the task, what do I do? Why, I utilize self-consistency of course! Since LLM agents are probabilistic agents, and can probably-maybe generate the correct answer, I can just perform the action multiple times and then determine the most common answer. Thus the rater is fired off in parallel 5 times as well.
The output here is JSON to ease parsing. OpenAI provides a JSON tokenizer for its models to enforce production of proper JSON formatting. PaLM 2 didn’t have this, and proved to be very unreliable in generating the correct JSON. For this reason whenever PaLM2 was utilized parallel plan creation was disabled; there was no reliable way to rate it.
The full process
…and there you have it. From objective to plan, we have the following flow:
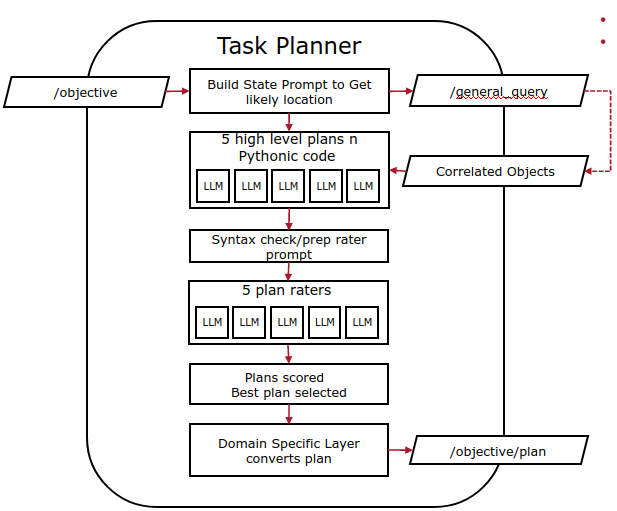
- Receive an objective in plain text
- Generate a state prompt based on the given objective
- Generate a set of plans in parallel (5x)
- Rate all generated plans at once by syntax checking them and allowing an LLM agent to judge them in parallel (5x)
- Average the scores and select the best one
- Execute the plan
Demos
So does it work? Yes; shockingly well actually. I have three videos below. A few notes before we dive into them; each video demonstrates GPT4-Turbo (specifically the gpt-4-1106-preview model) creating a plan for each objective. At the beginning of each video, the robot will cheerily exclaim what the objective was and add a little cute affirmation before starting to plan. Listen with sound on; not only will the robot read aloud the objective, but share its thought process. The “planning” time, wherein the robot sits there as it generates its task plans, rates them, and chooses the best, is edited out. The videos are fast-forwarded where nothing but driving occurs.
Each video has the same format; the primary screen is the simulation, the bottom left hand corner is our navigation map with LIDAR data and resulting local map for navigation, the upper right screen is the generated code for our task plan, and the bottom right is our AI streaming service mentioned above. All feedback from the AI’s actions are printed there.
Our first demo is the most complicated; the robot is told to look for medicine without knowing where it could be, and asked for a drink in an unclear awkward manner.
The robot openly shares its beginning thought process; we typically find medicine in bedrooms and bathrooms, so let’s look there. This is a perfectly reasonable logical jump to make that perfectly encapsulates what I thought would emerge with these models! Also exciting, but not easily spotted in the video, is how the AI guessed at possible labels of what it could be looking for. When the medicine label is announced, it’s announced with the label medicine, but the code expanded to include the possibility of the label being pills or pill_bottle as well for flexibility since it didn’t quite know what label would fit there.
def run():
print("We know that pills are often found in bathrooms and bedrooms, so let's check there")
search_terms = ["pill_bottle", "pills", "medicine"]
pills_found = []
...
# First, move to the bathroom as it's the most likely place to find medicine
print("Moving to the bathroom to look for pills")
success, msg = move_to_room("bathroom")
if not success:
print(f"failed to move to the bathroom - {msg}")
return fail()
# Look for the pills in the bathroom
print("Looking for pills in the bathroom")
pills_found = look_around_for(search_terms)
...
In our next demo we ask the robot directly for boots due to the weather. The robot isolates the core objective; getting our boots; and begins executing it. A simple fetch and go quest.
A final example - getting a drink for the user. Here the robot knew about a couple of drinks in the kitchen, though they had changed locations for this test. The robot is still able to locate and move to acquire one.
Results
Tasks were grouped and executed multiple times to try to extract some metrics of performance. It’s a small sample size, but paints an accurate picture from my experience with the system. Each was performed across PaLM 2, GPT-3.5-Turbo, and GPT-4-Turbo. The versions for the models in this project were:
| Model | Version |
|---|---|
| PaLM 2 | text-bison-002 |
| GPT-3.5-Turbo | gpt-3.5-turbo-1106 |
| GPT-4-Turbo | gpt-4-1106-preview |
Performance
A sample objective was selected and our AI planner was asked to generate a plan for it, 100 times per model. The performance results:
| Failure Type | PaLM 2 | GPT-3.5-Turbo | GPT-4-Turbo |
|---|---|---|---|
| Syntax Error | 0% | 3% | 0% |
| Average Lines | 41.75 | 40.7 | 72.12 |
| Longest Lines | 64 | 82 | 118 |
| Shortest Lines | 20 | 45 | 13 |
| Inference Time Avg (Seconds) | 5.00 | 5.28 | 32.82 |
| Longest Time (Seconds) | 11.18 | 14.14 | 66.13 |
Syntax errors was a failure to produce Python code across any of the parallel plan generations. This was detected through two methods, similar to our rating system. The first check was an AST syntax check of the code body (though I do scan for and remove common pre- and post-code inclusions, wherein models often wrapped code with markdown explanations of what it set out to do). The second was to scan for inclusion of at least some of the control functions for the robot, as their absence would imply the code would do nothing.
While code line length is not necessarily correlated with complexity or reliability of code, I saw such a correlation here. PaLM2 and GPT-3.5 performed similarly in both code length and generally complexity of approach towards presented problems, whereas GPT-4-Turbo routinely produced longer and more complex behavioral plans for the robot.
Finally inference times were similar for PaLM2 and GPT-3.5-Turbo, but significantly longer for GPT-4-Turbo. This is clearly a limiting factor for adoption of these techniques in real time applications.
Emergent Behaviors
There were some interesting behaviors for planning that was demonstrated across a couple of models that are tough to properly quantify.
Often agents would create tiers of backup plans; wherein the agent produced code that could deal with its first chosen action not resulting in an immediate success. For instance - if the plan said to look for the object, and immediately move to it, but had no prepared plan for what to do if the item was not immediately obvious to it, would be considered not having a backup plan. Alternatively, having the plan consider that its first chosen action might not work, and then doing something such as moving to another room, is a backup plan. Having multiple tiers of backup plans would consist of trying multiple rooms, or looking for different kinds of objects. GPT-4-Turbo almost always produced a backup plan to initial failure, PaLM 2 usually did, and GPT-3.5-Turbo rarely provided one. GPT-4-Turbo almost always had multiple levels of backup plans, which PaLM 2 rarely had, and GPT-3.5-Turbo never demonstrated.
Similarly, room-by-room search patterns was often demonstrated. Here the agent produces a set of instructions that would have the robot visit multiple locations in a hunt for a suitable item. GPT-4-Turbo always had some form of room-by-room search, PaLM 2 usually did, and GPT-3.5-Turbo only occasionally did.
Escalating difficulty
To try and see how viable this works, a series of tasks were created to test the agent’s ability to perform in increasingly difficult scenarios. The tasks were as follows:
| Task Difficulty | Explanation |
|---|---|
| 1 | target object(s) with known locations nearby to the robot |
| 2 | target object(s) with known locations in another room |
| 3 | target object(s) with unknown locations in the same room |
| 4 | target object(s) with unknown locations in predictable rooms |
| 5 | target object(s) with unknown locations in unexpected rooms |
For difficulty 4, we mean objects that the robot knows exist, but do not know where it is currently, in a room where one would expect it. For instance - food would typically be found in the kitchen. Alternatively, difficult 5 is the same but has the object in a room that makes little sense - such as a plate of salad residing in the bathroom.
Across 10 attempts per task per model. The results:
| Difficulty | PaLM 2 | GPT-3.5-Turbo | GPT-4-Turbo |
|---|---|---|---|
| 1 | 10 | 10 | 10 |
| 2 | 10 | 9 | 10 |
| 3 | 9 | 9 | 10 |
| 4 | 5 | 4 | 9 |
| 5 | 0 | 0 | 2 |
All models were able to handle short horizon tasks, and often short horizon searching. I did see that GPT-4-Turbo could handle most short or long horizon tasks that required searching, as long as the request fell within the bounds of predictability - if the item did exist where one would expect or where the robot last saw it, it would likely succeed.
The only 2 successes in the final task was, by my observation, only possible because the robot happened to see the item as it was driving past on its way to another room, placing it into memory and triggering do_i_see functions to redirect the robot there. I view the lack of success in this task as a positive - it serves as an impromptu ablation survey that provides demonstrable proof that the planners were indeed using their contextual understanding of their world to shape their planning.
Plans generated by the agents were able to solve many of the typical “fetch” requests we were able to give it. Often I was surprised by interesting logical jumps the agents made. Failures were equally interesting; sometimes extrapolating additional functions we did not tell it about in a similar naming style, or sometimes just failing to produce a plan at all.
So is this a big deal?
My work? I think it’s fascinating and cool, but it seems like a small ripple in an ocean. This project was to prove my initial hunch (and, okay, sure, secure a good grade too) that these LLM agents are going to change how planning tasks are done in robotics. There’s a blue ocean of possible research, techniques, frameworks, and technologies to be developed here. Suddenly complex breakdowns of tasks and composition of long horizon planning seems… not easy, but at least possible without expert programmers or extensive reinforcement learning agents.
My prediction? We’re going to not only see a continuation of LLM powered embodied agents, but also smaller models with fine tuning. Cheaper hardware will start to become the focus for robotic-oriented LLMs as we determine best approaches and limitations on larger models. It’s already likely that we’re going to see a slew of mobile-oriented chips for LLMs for personal devices; some of this technology will absolutely trickle over to robotics applications.
Next Steps
This project was highly limited in its scope by time; I had to deliver the project by a set date for a grade. It does capture my attention and promises to expand to some interesting future work I hope to get to soon.
- In Progress Self Rating
- One of the original design goals was to have an LLM agent self-assess its performance or react to new information, such as spotting new objects in the environment, or realizing that a passageway has been blocked. Unfortunately, due to inference time of our language model providers, I limited replanning to failure of a plan as designated by the agent ahead of time. Agents that could assess the progress of its plan and decide to replan or incorporate new information could create far more reliable agents and be applied to more complicated tasks.
- Iterative Planning
- Plan generation, despite parallel generation and rating, was still performed in a single inference run with the state prompting generated at query time. Instead, an agent could perform iterative human-language question and answer cycles with the state management system to refine its own understanding of the environment prior to plan generation. This could result in a better understanding of the world state and more complicated tasks.
- Fine-Tuning
- Fine tuning is the process of performing additional training on a pre-trained model, orienting the agent to produce the output desired without the need of extensive prompt engineering. Generating an extensive dataset of objectives to plans could produce significantly more complex and reliable plans by the agent, resulting in a better performing robot. Similarly, recent works suggest that you can match existing performance of larger general application models with far smaller models via fine-tuning, allowing weaker consumer oriented hardware to run application-specific models. It was not pursued during this project due to time and resource constraints.
- Functional Development
- I provided a set of core functions that allowed the robot to control its hardware with an easy interface. It would be interesting to give the agent smaller “building blocks” of core robot functionality, and then have it build increasingly more complex functionality iteratively based on what it wishes to do. This was demonstrated in Code As Policies, For instance - we provided a
look_around_forfunction, which spins the robot in place at intervals, querying the vision system if it recently saw an item of a set label. Instead, we can give the agent just the vision query and movement code, and expect it to eventually develop equivalent functionality over iterative generation. - Rating Agent Improvements
- Our rating agent was ”good enough” in that it produced plausible explanations for its resulting scoring of each plan. I did not have time, however, to fully explore the effectiveness of this agent. Not only would it be wise to create a human-rated dataset of plans, but possibly creating a custom fine-tuned model as well.
- Automated Prompt Generation
- I engineered the prompts through trial and error, though recent works suggest that prompts can be generated with genetic algorithms or reinforcement learning approaches. It would be a worthwhile endeavor to try to improve performance through use of these techniques to develop the best prompts for a given application and discover best practices for future projects.
- Tokenizers
- Recent applications have demonstrated the improvement of agents in applications requiring specific output formats or actions by using specialized tokenizers that only output compatible tokens. For instance - OpenAI’s JSON tokenizer will ignore suggested tokens by the model that would produce invalid JSON. Similarly, other tokenizers have been produced for various languages such as Python. These increase the probability that the agent will produce correctly formatted output. Additional research into a robotic action oriented tokenizer can be done to produce more reliable results from smaller models, but would require custom models as existing model providers within this work do not allow custom tokenizers. This has been demonstrated already for some sensoriomotor transformer models.
- Multiple Robotic Agents
- I’ve listed it as a possible project before, but it would be interesting to see how multiple LLM powered agents with a set of individual objectives would interact an environment wherein their tasks required some degree of cooperation and coordination.
Discussion
Like what you read? Have questions? I’m always eager to talk about robotics and AI. Reach out to me or hit me up on Mastodon, e-mail, or Discord.