Multi-Turn Credit Assignment with LLM Agents
tldr;
A paper caught my eye, proposing a way to treat individual agent calls in multi-turn agent training as individual steps. The key contribution - an easy, intuitive method of assigning credit to each step, for quicker training.
Introduction
A paper - Reinforcing Multi-Turn Reasoning in LLM Agents via Turn-Level Credit Assignment - caught my eye, prompting me to present a paper club on it. the paper presents a simple, novel idea in how to mathematically assign credit to an agent with multi-turn trajectories. While focused on agentic LLM training (and even then in a critizisable limited manner), I suspect that it could be applied to additional model archetypes.
The Challenge
Reinforcement learning can be notoriously difficult in complex domains because it’s hard to tell the model exactly what actions were beneficial or detrimental. How can you determine, mathematically, what actions directly contributed to a specific outcome? Even with experts designing heuristics and engineering rewards to build a set curriculum, there’s still a disconnect from the final score, the model’s behavior, and the resulting adjustment to the model from the outcome.
Consider a robot arm being trained to throw a basketball through a hoop. You could design a set of rewards wherein you can reward picking up the ball, tossing it at a set speed, the arc of the ball, and proximity of the ball to the net. This doesn’t really work in practice though - it is unclear when the rewards are jumbled together what actions actually contributed to the final reward as they’re all combined when it comes time to adjust the model. Plus reinforcement learning is notorious at finding ways to “cheat” scores - as demonstrated when I tried to evolve traffic light controllers.
The more common alternative is to utilize sparse rewards - reward only 0 or 1 to the agent if it succeeds what you want it to do, or not. We’ve acheived amazing things with this simple framework, but it means that long running continuous tasks or multi-step tasks are very difficult to train. This is one of the prime reasons reinforcement learning is so sample inefficient and often difficult to reproduce stable behavior.
Turn-Level Training
Typically, training a model to perform a multi-step task would look like the following (note that the paper, and my talk, focuses on LLM agents, but this could in theory be applied to any agent architecture):
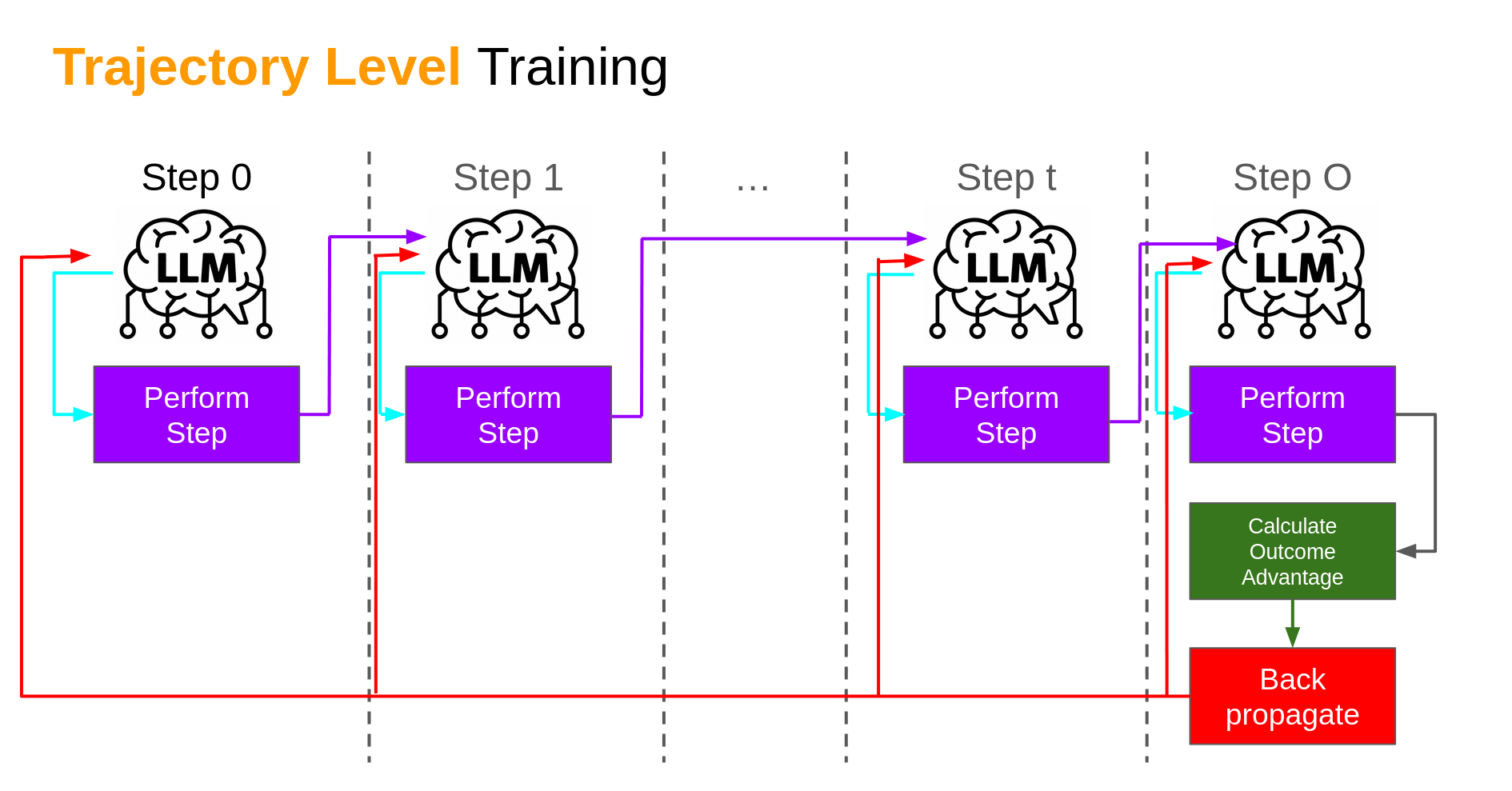
The core idea - the agent produces an output based on a state, which is fed into the same agent agent again (for the LLMs, it’s a set of tokens in the generated prompt - it’s the observation of state for more basic models). This is repeated for each turn (be it a predefined length or variable), until we hit a terminal state. The reward is then calculated in whatever manner the designers have chosen, and then a back propagation (or whatever methodology for adjusting model the model). The longer the series of steps (turns, for this paper), the more disconnect between what the model did at an earlier step than the final outcome.
The paper’s authors suggest an alternative:
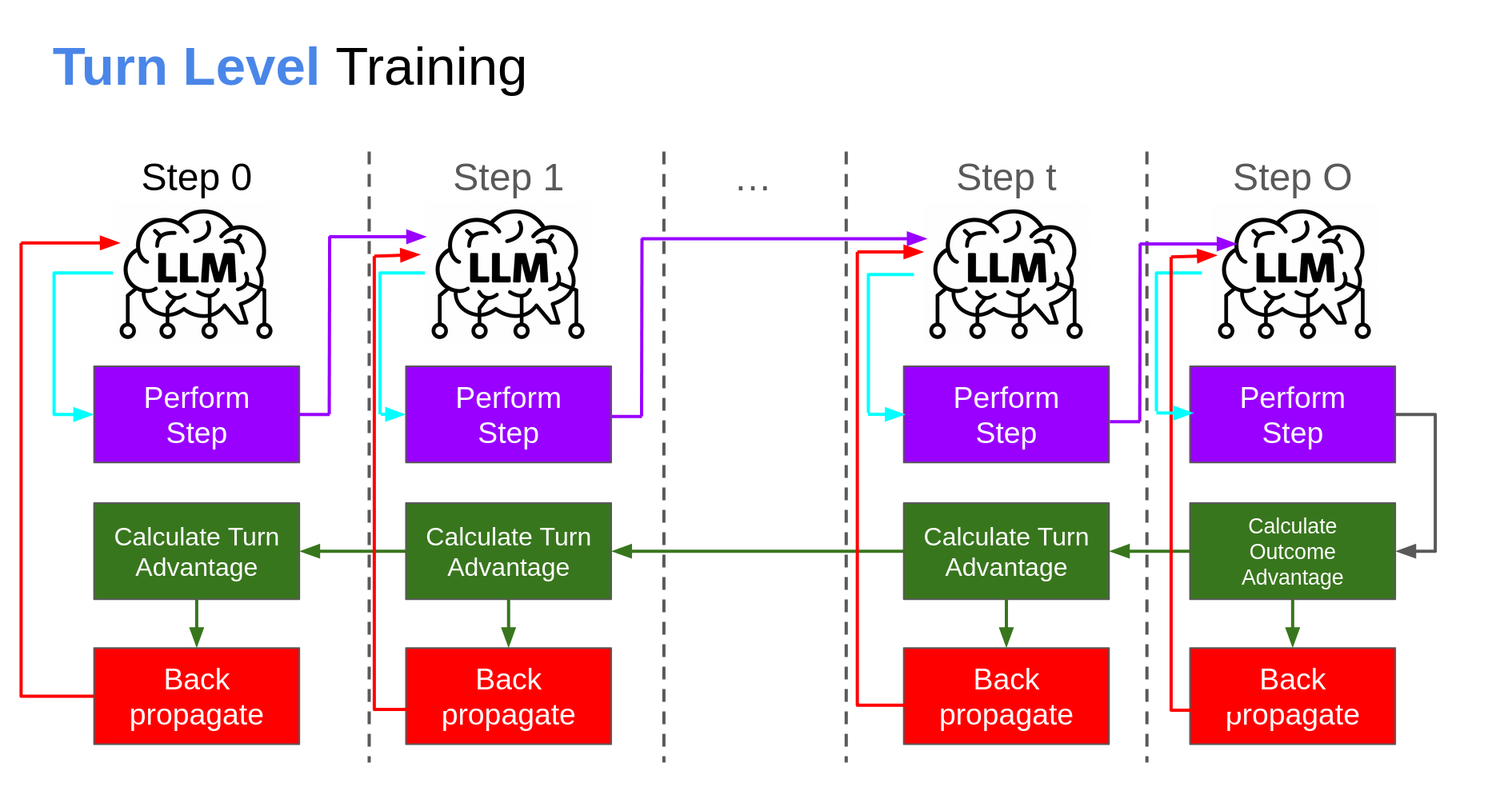
For a singular trajectory rollout, take the model output for the individual steps and apply a calculated turn-based reward that also incorporates some ratio of the final outcome. The authors adjusted GRPO (which I talk about at length here) - which is an adjustment of PPO for LLM training, discussed here - but this technique adaptable to any learning algorithm. The mathematics are as such (with latex coloring aided by my ELI5 Equation Tool):

The core change from standard GRPO lies within the advantage term. Advantage is typically:
$$A_i = \frac{Q_i(s, a)}{V(s)}$$
Where Q is the Q-value - the reward given for a given state and the resulting action - and V is the value function - the expected return for a given state. Or, reworded - how good is the action we took from this state versus the expected average of what one would achieve in that state. This makes the A advantage a measure of how good or bad was this action compared to what we could normally achieve in that state? To incorpoate multi-turn rewards for that specific turn, we instead do:
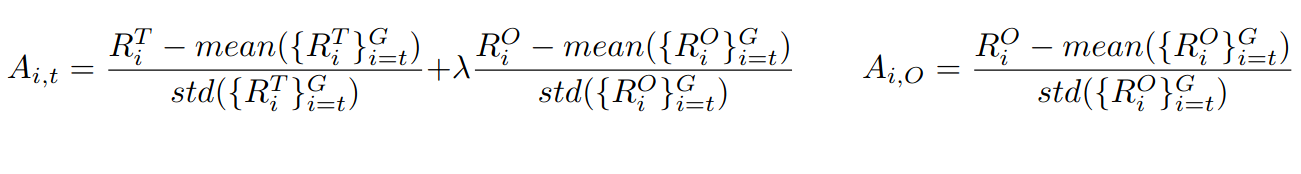
For non terminal turns, the advantage is the resulting turn reward scored with the added final outcome reward score multiplied by a value λ (a relevance factor). For terminal turns, the advantage is just the final outcome reward score. The relevance in this paper was set to 0.2, but could be a hyperparameter adjusted if you know the expected turn action (which was the case in this paper) or for the particular tool activation the agent chose.
The math, clarified:

This subtle change empowers the agent to better attribute success and failure, resulting in stronger learning signals and overall improved reasoning capabilities. It’s clever in its simplicity.
Limitations and Open Questions
While the results are promising, the paper has a notably narrow scope The environment used a simplified Wikipedia search and answer task, limiting itself to a hard-set expected 2-turn agent. It also uses simplified verifiers - their term for the logic checking LLM model output to generate rewards.
This leaves me with a few open questions
- How well does the multi-turn advantage generalize to more dynamic and less structured environments? Or non LLM focused models?
- Does this methodology hold up on variable length or longer turn agents?
- Could integrating richer reward generation models, like DeepSeek’s GRM (discussed here), further enhance the method’s flexibility and capability?
I am fascinated by the idea of having a complex robotics agent utilizing this to generalize a model’s performance in long term mixed-action tasks by utilizing a generative reward model approach with this.